
AI Industry-Academia Insights
AI行业资讯专家精选No.26:世界首例机器人辅助白内障手术;何恺明提出JiT架构;2025年AI新范式盘点;Meta发布“一键抠音”模型……
发表日期: 2026年1月15日
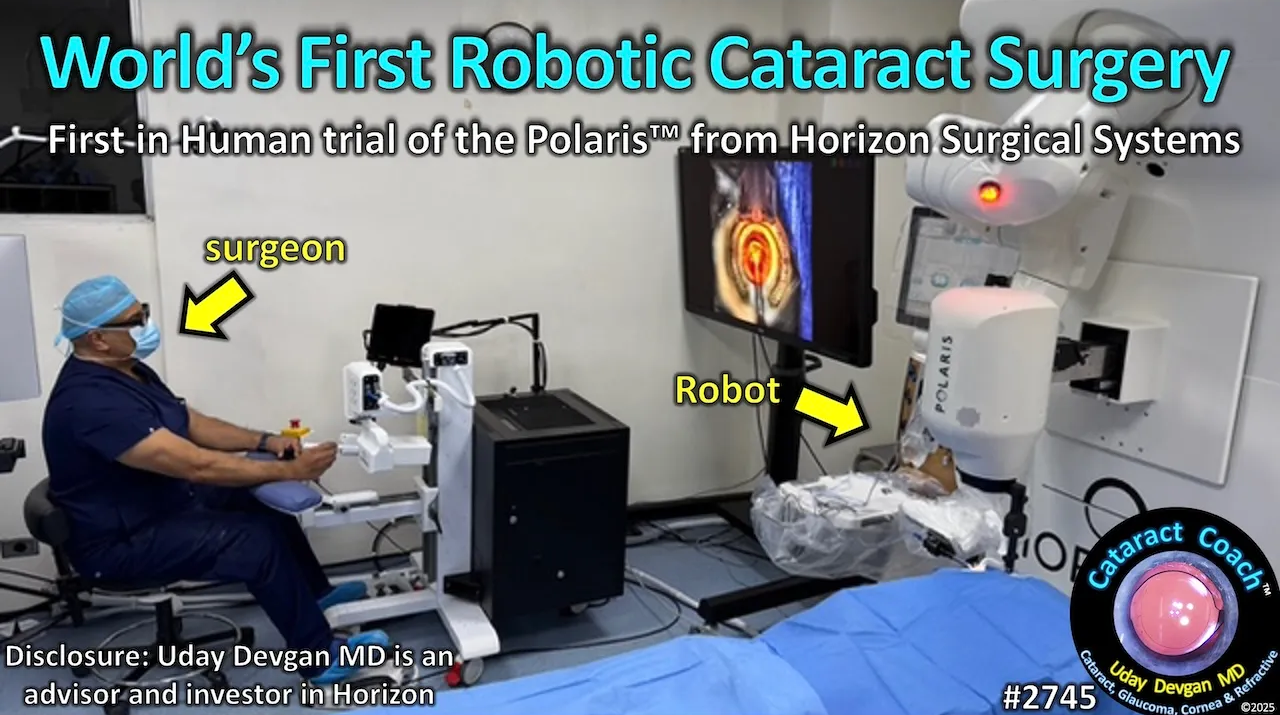
1.世界首例!Polaris完成机器人辅助白内障手术
2025年10月8日,Horizon Surgical Systems公司自主研发的Polaris机器人手术平台成功完成了世界首例机器人辅助的眼科白内障手术,标志着机器人技术正式进入全球手术量最大的显微外科领域。
当今,每年数千万例白内障手术仍完全依赖手工操作,而医生在操作上的细微差异可能会影响手术效果,甚至引发各种并发症。为了确保眼科手术始终具有高精度、准确性和安全性,Horizon Surgical Systems开发了一款专为眼科手术场景设计的机器人辅助系统Polaris,它具备小于1微米的工具尖端精度和无颤动的机器人手臂,能够在手术过程中实现精准操作和精确定位。
同时,Polaris还配备了先进的数字显微镜和图像处理系统,能够实时捕捉手术区域的图像,并提供高分辨率、高清晰度的视觉反馈。通过深度学习算法,Polaris能够分析手术数据,预测手术风险,为医生提供科学的手术建议。其小于20毫秒的快速反应时间,以及显微镜下的高精度视觉效果和实时组织切片能力,为医生提供了前所未有的手术控制力。
未来数月内,Polaris还将开展更多病例验证,目标是获得美国FDA批准并实现商业化。
目前,全球多家公司正在积极开发各种类型的眼科手术机器人系统。以色列ForSight公司的Oryom微型手术机器人正在准备首次人体临床试验;荷兰Preceyes BV公司开发的产品已成功应用于玻璃体视网膜手术,获得欧盟批准并进入多国临床;中山大学中山眼科中心研发的“5G远程微米级眼科手术机器人”实现了跨时空限制的高精度手术操作;北航团队成立的衔微医疗正在研发超显微眼科手术机器人及眼科智能器械。
这些进展表明,眼科手术机器人领域正迎来快速发展期,未来可能彻底改变眼科手术的教学和实践方式。
链接:https://cataractcoach.com/2025/11/11/2745-worlds-first-robotic-cataract-surgery/
2.让扩散模型返璞归真,AI大神何恺明提出JiT架构
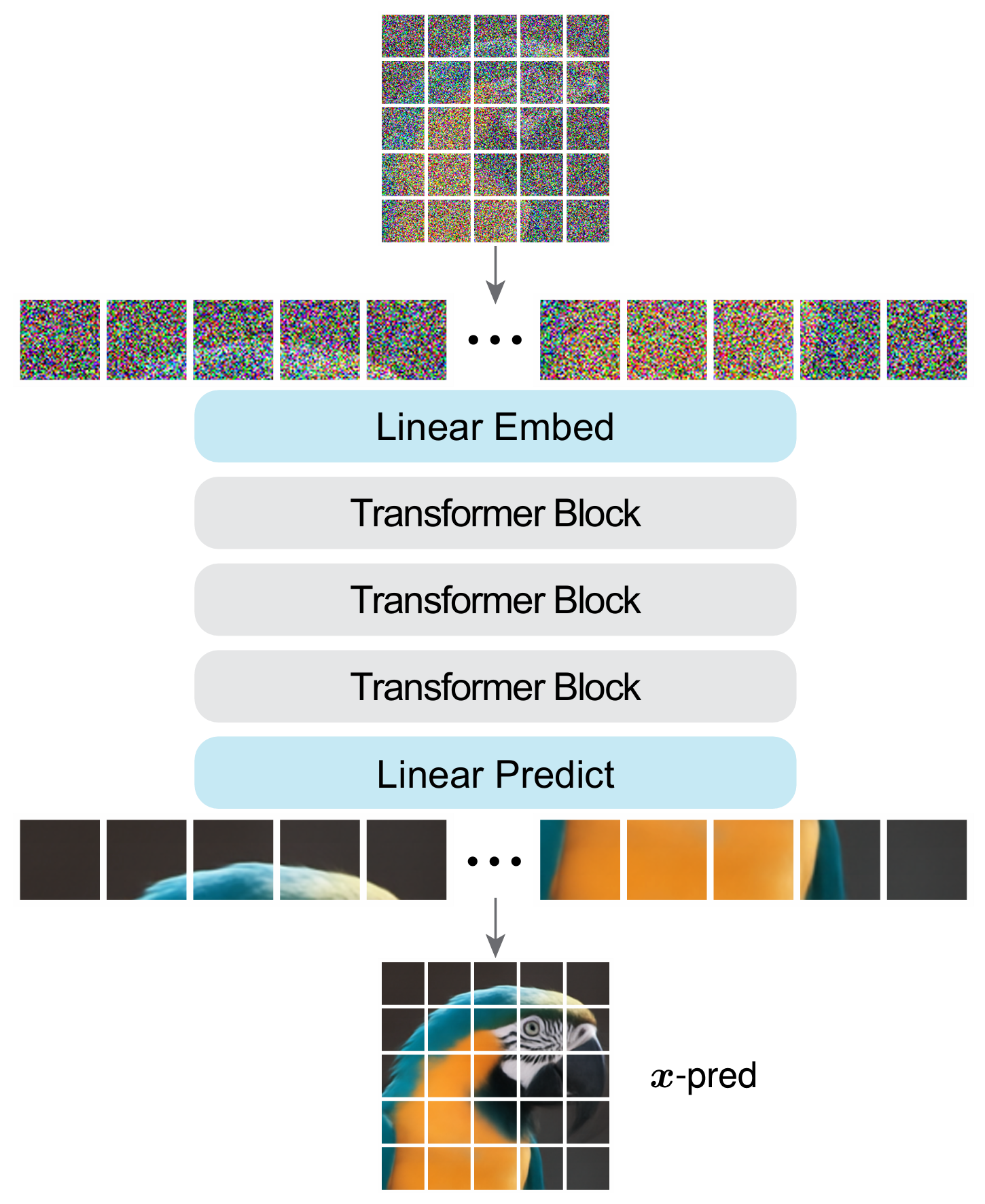
2025年11月17日,ResNet之父、AI大神何恺明提出了JiT(Just image Transformers)架构,仅使用简单的Transformer就能成为强大的生成模型,无需tokenizer、无需预训练,也无需额外损失项进行约束。
JiT遵循ViT的设计理念,完全从像素开始,用一个纯粹的Transformer进行denoise(去噪)。它将原始像素切成大Patch(维度可高达3072甚至更高)直接输入,唯一的改动是将输出目标从预测噪声变成直接预测干净的图像块。该架构能够有效处理极高维的per-patch表示,而无需依赖潜空间压缩或模型扩容,从而避免了传统像素级扩散模型的观测维度灾难。
得益于高效的架构设计,该模型在计算上十分友好,当分辨率翻倍时,计算开销并未如传统方法那样呈平方级增长。在不依赖任何复杂组件或预训练的情况下,JiT在ImageNet 256×256和512×512上分别达到了1.82和1.78的SOTA级FID分数。
在扩展能力上,该模型同样表现出色。一方面,模型性能随参数量增大而持续提升;另一方面,在更高分辨率下,大模型不仅未出现性能退化,反而因任务难度增加而缓解了过拟合问题。即使将Patch尺寸扩大至64×64,让输入维度高达一万多维,只要坚持预测原图,无需增加网络宽度也能实现高质量生成。
实验结果显示,在低维空间中,预测噪声和预测原图的表现难分伯仲;但一旦进入高维空间,传统的预测噪声模型彻底崩溃,FID(越低越优)指数级飙升,而直接预测原图的JiT却依然稳健。
这项研究回归本源,有力论证了直接预测干净数据比预测噪声或预测流速更本质且更有效,为在原始自然数据上构建基于Transformer的扩散模型探索了一种自洽的范式。
链接:https://arxiv.org/abs/2511.13720v1
3.重塑未来:2025年AI领域的里程碑突破与范式演变
2025年12月20日,OpenAI创始成员之一的Andrej Karpathy在《2025 LLM Year in Review》的推文中探讨了2025年AI领域的一些重要突破和现象级产品,认为这些范式转变将完全重塑行业格局。
RLVR驱动推理进化,开启LLM发展新拐点
RLVR(基于可验证奖励的强化学习)是训练生产级LLM的一项颠覆性新技术。它通过在可验证环境中训练模型,利用客观且不可投机取巧的奖励函数,促使LLM自发学习推理策略,包括分解问题、探索中间步骤和纠错。同时,RLVR还允许更长的优化过程,通过调节“推理轨迹长度”和“思考时间”进一步释放性能潜力,为LLM发展开辟了全新路径。
Cursor飞速崛起,颠覆开发者与AI协作范式
Cursor是一个开创全新应用层级的产品,其飞速增长证明了基础大模型之上存在巨大的应用潜力。它不仅负责上下文工程,还通过端侧编排,将LLM调用组织成复杂的DAGs(有向无环图),在性能与成本间找到平衡。同时,Cursor利用隐私数据、传感器和反馈回路,将通用LLM微调为特定领域的“专家”,为用户创造实际价值。这种模式为LLM应用的发展指明了新方向。
回归本地,ClaudeCode重新定义AI智能体
ClaudeCode以一种全新的、独特的与AI交互范式,完美阐释了Agent智能体的真正面貌。它通过循环方式将工具调用与推理有机串联,解决了上下文过长的问题。与云端部署的智能体不同,ClaudeCode选择直接运行于本地主机,充分利用现有的计算环境、密钥、配置和系统资源。这标志着智能体开发从云端向本地的回归,更契合当前AI能力发展参差不齐的过渡阶段。
打破门槛,VibeCoding掀起全民编程革命
VibeCoding掀起了一场编程领域的全面革命,赋予人们通过对话即可构建程序的能力。VibeCoding让编程变得简单直观,任何人都能轻松实现创意,无需掌握传统的编程知识。同时,专业人士也能利用它更高效地编写复杂软件。日常项目(比如menugen、llm-council和HNtimecapsule)都可以快速完成原型化。这一模式重新定义了软件开发的方式,让代码变得更轻量化。
构建LLM GUI早期雏形,NanoBanana震撼出世
Gemini NanoBanana是目前最具范式转变意义的模型之一。与传统的生成模型相比,它不仅能高精度生成图片,还可以理解图片中的物体,精准识别定位、角色、物品、区域等,并将多张图片进行融合。这极大降低了图片编辑门槛,提升了效率。NanoBanana突破性地统一了视觉理解、推理与生成,将这些能力交织于模型权重中,构建了一个全新的LLM GUI交互范式。

链接:https://karpathy.bearblog.dev/year-in-review-2025/
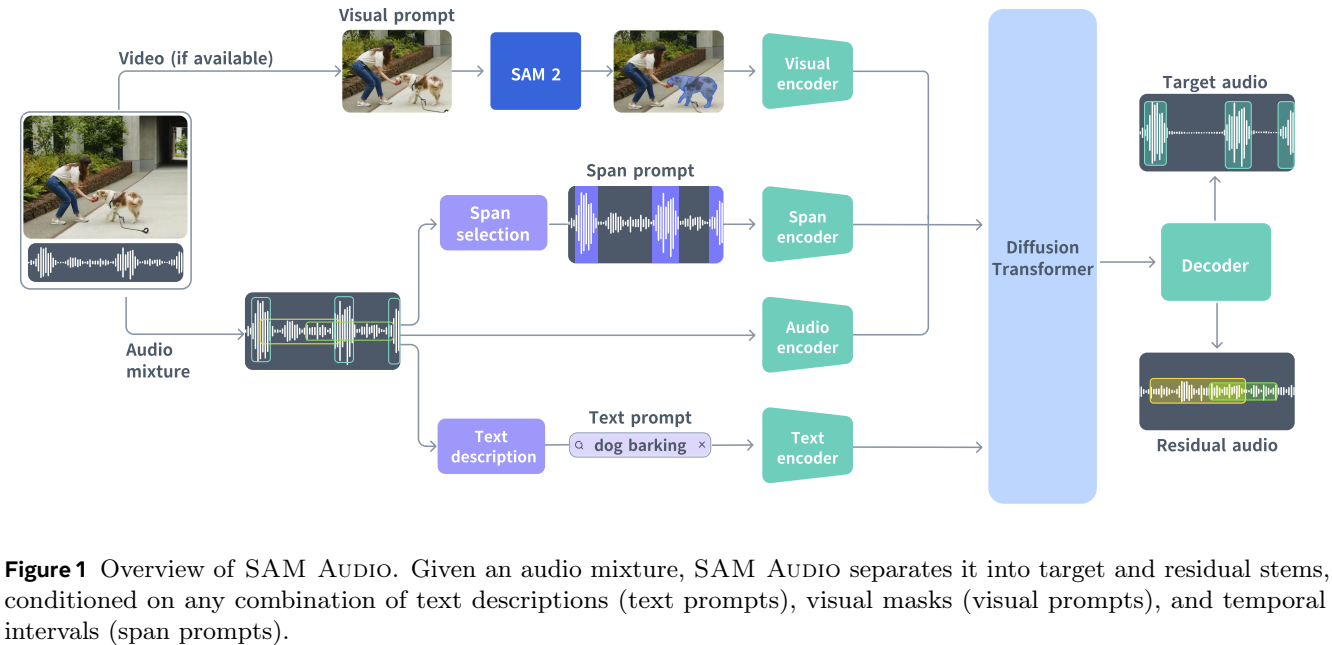
4.一键“抠音”,Meta开源音频分割模型SAMAudio
2025年12月16日,Meta发布音频分割模型SAMAudio。该模型通过多模态提示(文本、视觉、时间维度),能够轻松从复杂的音频混合中分离出任意声音,从而彻底改变音频处理方式。
在技术架构上,SAMAudio采用了基于流匹配扩散Transformer的生成式建模框架,能够将混合音频与提示信息编码为共享表示,从而生成目标音轨。同时,它配套构建了完整的数据引擎,融合了自动化多模态提示生成与伪标签技术,解决了高质量音频分离数据稀缺的问题。这使得模型能够灵活地进行开放域的音频分割,既适用于真实环境中的应用,也适用于专业音频场景。
SAMAudio不仅将先进的计算机视觉能力扩展到了音频领域,还融合了多种开源组件和前沿研究成果。其核心组件PE-AV采用大规模多模态对比学习方法,并基于超过1亿条视频进行训练,确保了数据覆盖的广泛性和模型的强泛化能力。
性能评估表明,SAMAudio不仅在通用音频分离方面显著领先于以往工作,还在所有音频类别(包括语音、音乐以及通用声音)上达到了最佳领域专用模型的性能水平。
目前,Meta已将SAMAudio整合到AI创意工具平台Segment Anything Playground中。用户可以从音频和视频素材库中选择内容,或上传自己的素材,以探索SAMAudio的能力。此外,Meta还与助听器制造商开展合作,希望通过SAMAudio推动无障碍技术的发展。
链接:https://ai.meta.com/blog/sam-audio/
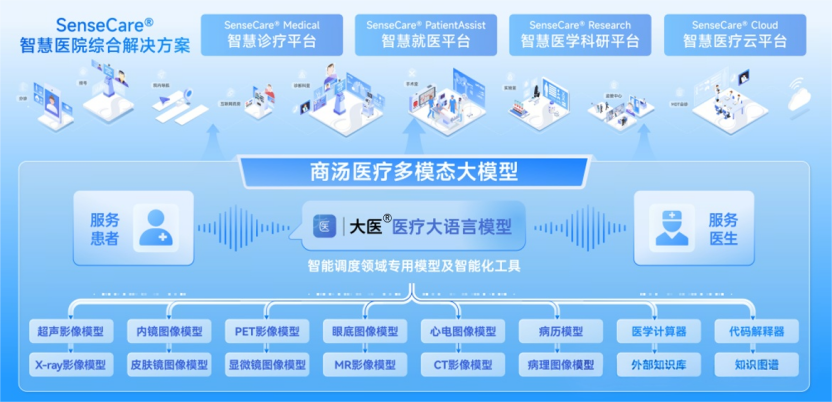
5.半年融资10亿,商汤医疗剑指“医疗世界模型”
2025年,商汤医疗正式启动A轮融资,半年内累计融资规模已达10亿元,迅速跻身准独角兽行列。商汤医疗的AI体系采用“通专融合”路线,通过自主研发的医疗大语言模型“大医”统筹调度多模态基础模型群,并结合医学专病知识库及工具集,构建了系统化、场景化的能力平台。
技术方面,大医搭建了面向医疗场景的工业级RAG框架。在生成回答前,模型会先进行证据溯源和知识校验,从源头上降低“幻觉”问题,显著提升输出内容的可靠性和实际可用性。同时,大医构建了超250B tokens(约4000亿汉字)、覆盖100+医学学科的高质量语料库,并持续跟踪高价值语料的新增与既有语料的效果变化,不断优化训练数据结构。
为实现大医与多模态基础模型群的高效协同,商汤医疗开发了“大医Bots”智能体开发平台和多模态基础模型应用生产平台,形成了“数据-模型-场景-产业”的完整闭环。基于这一闭环,商汤医疗打造了由医疗大模型驱动的“SenseCare智慧医院”综合解决方案,涵盖智慧诊疗平台、智慧就医平台、智慧医学科研平台、智慧医疗云平台等。
在专业测试集中,大医整体表现位居第一,超越了DeepSeek满血版、GPT-5等通用模型。
目前,大医已上线40余款AI模块,覆盖肺、心脏冠脉、头颈血管、肝脏、肌骨等十余个临床方向,为各类医疗场景提供开放应用。
未来,商汤医疗将以医疗大模型驱动的“未来医院”设计者与赋能者为目标,致力于构建医疗领域的世界模型,实现对医疗场景的全面感知与深度理解,塑造可自主学习、持续进化的未来智慧医院。
链接:https://www.sensetime.com/cn/product-detail?categoryId=51134395
6.登顶权威医疗榜单,蚂蚁·安诊儿医疗大模型正式开源
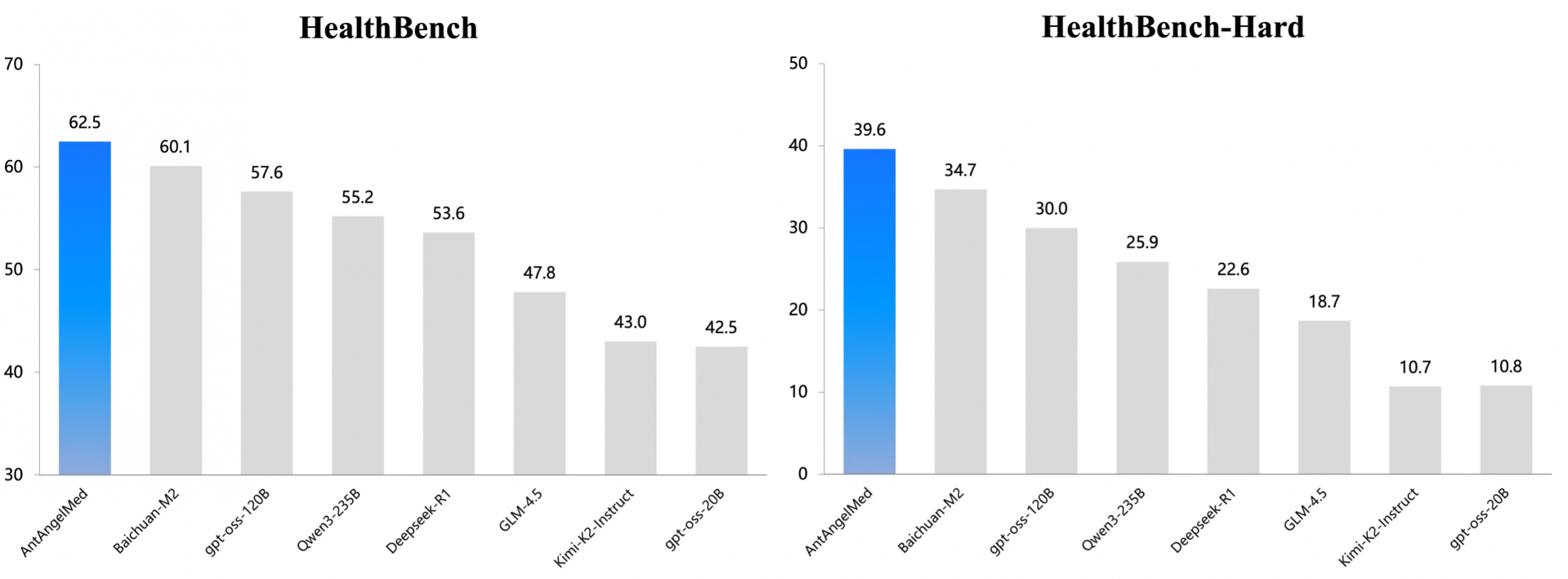
2025年12月20日,蚂蚁集团联合浙江省卫生健康委正式开源其自研的蚂蚁·安诊儿医疗大模型(AntAngelMed)。该模型是迄今为止参数规模最大的开源医疗模型(100B总参数),不仅能够为大众提供专业医生般的解答,还能助力医生高效精准地进行临床判断。
AntAngelMed继承了百灵大模型Ling-flash-2.0的高效混合专家(MoE)架构,并在一系列核心设计上进行了全面优化。相比同等规模的Dense架构,AntAngelMed的效率提升了7倍,能够在H20硬件上实现超过200 tokens/s的推理速度,展现了极致的性能与效率。
在深度训练过程中,AntAngelMed通过持续预训练向基座模型注入大规模高质量医学语料,并利用多源异构高质量指令数据进行监督微调。同时,它采用先进的GRPO强化学习算法,通过双阶段强化学习路径对模型能力进一步优化提升,实现了逻辑推理能力与同理心、安全边界意识的高度统一。
在OpenAI发起的HealthBench以及国家人工智能应用中试基地(医疗)的MedAIBench等权威评测基准中,AntAngelMed表现出色,超越了DeepSeek-R1、Qwen3、OpenAI GPT-OSS等模型,充分证明了其在真实、复杂医疗环境中的可靠性与专业性。
AntAngelMed这种“通用智能+医疗专长”的全栈能力闭环,标志着开源AI医疗模型进入了高效、专业、安全三者兼顾的新阶段。通过开源,蚂蚁集团希望进一步推动AI技术在医疗领域的普及与应用,为行业树立新的标杆,并为全球医疗智能化发展贡献力量。
链接:https://github.com/MedAIBase/AntAngelMed
7.华为昇腾实现智谱GLM-4.6V系列部署支持
2025年12月8日,智谱AI正式上线并开源GLM-4.6V系列多模态大模型。该模型将训练时的上下文窗口提升至 128k tokens,在视觉理解精度上达到同参数规模的 SOTA(当前最优)水平。同时,华为昇腾首次支持了 GLM 系列开源模型与 xLLM 开源推理引擎的生态合作,并在 Atlas 800 TA3 硬件上成功实现高效推理部署。
针对传统工具调用多模态内容时需要多次中间转换的问题,GLM-4.6V 从设计之初便围绕“图像即参数,结果即上下文”的理念,构建了原生多模态工具调用能力。它将 FunctionCall(工具调用)能力直接融入视觉模型,完整打通从感知、理解到执行的闭环,这使得模型能够在复杂场景中独立完成任务链。
在性能显著提升的同时,GLM-4.6V 系列模型相较上一代实现降价 50%,API 调用价格低至输入 1 元/百万 tokens、输出 3 元/百万 tokens,其中 GLM-4.6V-Flash 版本已免费开放。目前,该模型已在智谱开放平台及多个开源社区提供模型权重与推理代码,供开发者和研究者快速集成。
GLM-4.6V 在 MMBench、MathVista 等30 多个主流多模态评测中表现优异,整体性能超越DeepSeek-V3.2-Exp,是目前国内最强的 Coding 模型,支持“过目不忘”的长视频理解和多文档分析 。
华为昇腾作为自主创新的算力底座,为 GLM-4.6V 提供了强大的硬件支持。xLLM 推理引擎专为昇腾芯片优化设计,提供企业级的服务部署,适用于大语言、多模态理解、文生图/文生视频、生成式推荐等各类 AIGC 场景。同时,其服务-引擎分离式架构实现了对计算和通信资源的极致复用,推动了硬件效能的突破性跃升。

链接:https://github.com/zai-org/GLM-V/blob/main/examples/Ascend_NPU/README_zh.md