
AI Industry-Academia Insights
AI行业资讯专家精选No.21: 一文看尽WAIC开幕式干货;多模态医学图像多篇成果登上Nature正刊
发表日期: 2025年8月9日
一、诺奖得主杰弗里•辛顿:人类或是大语言模型!一文看尽WAIC开幕式干货
世界人工智能大会(WAIC)是国内最高规格的AI领域行业大会之一,7月26日,在WAIC 2025开幕主论坛上多位大腕云集,金句频出。
全球瞩目的“深度学习三巨头”之一,2024年诺贝尔奖得主、2018年图灵奖得主杰弗里•辛顿认为,大语言模型的理解语言的方式几乎和人类一样,人类可能就是大语言模型。未来超级智能将很容易操纵人类,人类要避免“养虎为患”,因此要建立国际社群来预防AI操纵世界,推动AI向善。
图灵奖得主、中国科学院院士、上海期智研究院院长姚期智认为要预防AI鸿沟,让所有国家受益于这一场AI革命。美国约翰霍普金斯大学教授吉莉安•哈德菲尔德认为要通过贸易结构变革以及具体的技术交易设计,来抹平AI鸿沟。蒙迪与合伙人公司总裁克雷格•蒙迪认为,随着用量变大,就像移动通信与手机技术一样,大模型的使用价格将变得足够低,使得更多产业和企业受益。美国加州大学伯克利分校教授斯图尔特•罗素认为,当前AI公司及各国、各地区间的AGI(通用人工智能)竞赛毫无意义,AGI的实现需要依托无限的财富创造能力,而AI理应成为全球共享的公共资源。
MiniMax创始人、首席执行官闫俊杰认为,未来的AI产业必然会呈现多玩家共存的格局,AI的普惠性将进一步提升,AGI必然会实现,且这一目标需要AI企业与用户共同推动。

https://mp.weixin.qq.com/s/wOPQBpGosVOI5vATCNrLgg
Multimodal generative AI for medical image interpretation,介绍了多模态生成式人工智能(GenMI)在医学图像解读和报告生成中的应用,强调通过整合多种成像方式和临床背景信息,提升报告的准确性和全面性,并提出了“AI住院医师”范式以辅助临床医生和患者。
Deep evidential fusion with uncertainty quantification and reliability learning for multimodal medical image segmentation,提出了一种多模态医学图像分割的深度证据融合框架,结合Dempster-Shafer证据理论和深度神经网络,提取各模态特征并映射为质量函数,经上下文折扣校正后融合,有效量化分割不确定性并提升准确性。
Advancing multimodal medical image fusion: an adaptive image decomposition approach based on multilevel Guided filtering,提出了一种多模态医学图像融合方法,通过多级引导滤波将图像分解为小尺度、大尺度和背景三个子层,再用脉冲耦合神经网络和最大值融合策略对子层进行融合,最终合成融合图像。
Simultaneous tri-modal medical image fusion and super-resolution using conditional diffusion model,提出TFS-Diff模型,可同时完成三模态医学图像融合与超分辨率处理,通过通道注意力模块整合多模态信息,避免多次处理致信息丢失,实验效果优于现有方法。
近半年,多模态医学图像的论文多次入选CVPR、AAAI、中科院TOP刊等顶会/顶刊,尽管这一领域的研究竞争日益激烈,但在罕见病诊疗、基层医疗、多组学融合等场景仍然存在大量创新空间。
在模型架构方面,Kimi K2 采用了与 DeepSeek-V3 相似的多头隐式注意力机制,并通过多项改进将专家总数从 256 提升到 384 以提高稀疏度,同时将注意力头数从 128 降至 64 以减少推理开销。
在训练数据方面,改写了流水线扩增高质量 token,包括将知识型数据改写成多样风格、把数学文档转化为「学习笔记」形式。
在后训练阶段,在有监督微调中构建了覆盖多领域的大规模指令数据集,为工具使用能力合成了包含 3000+真实工具和 2 万+合成工具的交互数据。在强化学习阶段,设计了可验证奖励的「训练场」用于提升数学、编程等能力,并引入模型自评机制处理创意写作等主观任务。通过 PTX 损失函数和动态 temperature 调节等技术,确保了模型输出的可靠性和一致性。
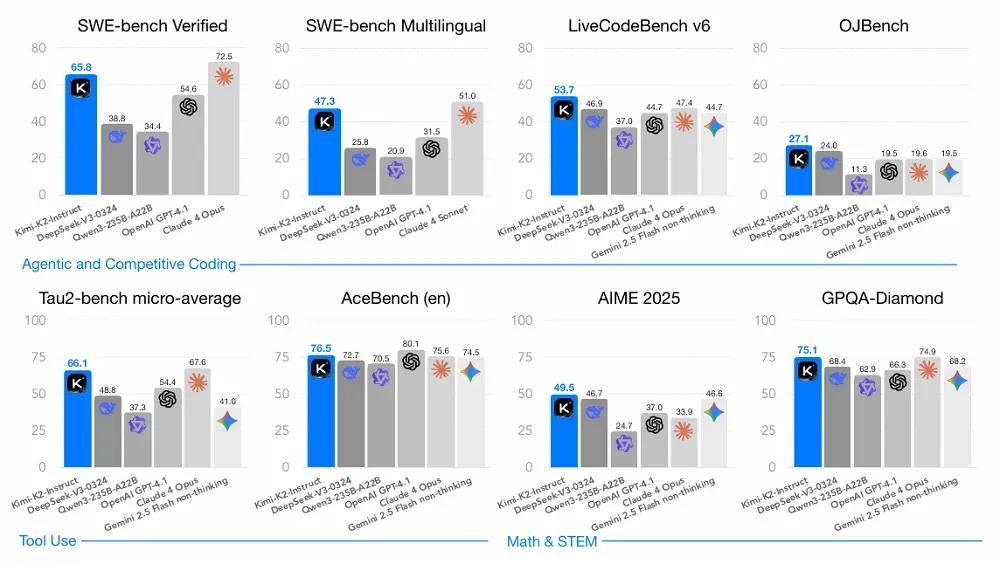
测试中,Kimi K2在编程、工具使用、数学推理等维度表现优异,获得 14 项全球 SOTA 和 24 项开源模型 SOTA。在不开启思维链的情况下,多项测试成绩已超越主流开源模型并接近头部闭源产品。
https://mp.weixin.qq.com/s/LEP1z7IiEazNL53BcvzB4w
四、MIT 新作揭示 LLM「波将金式错误」
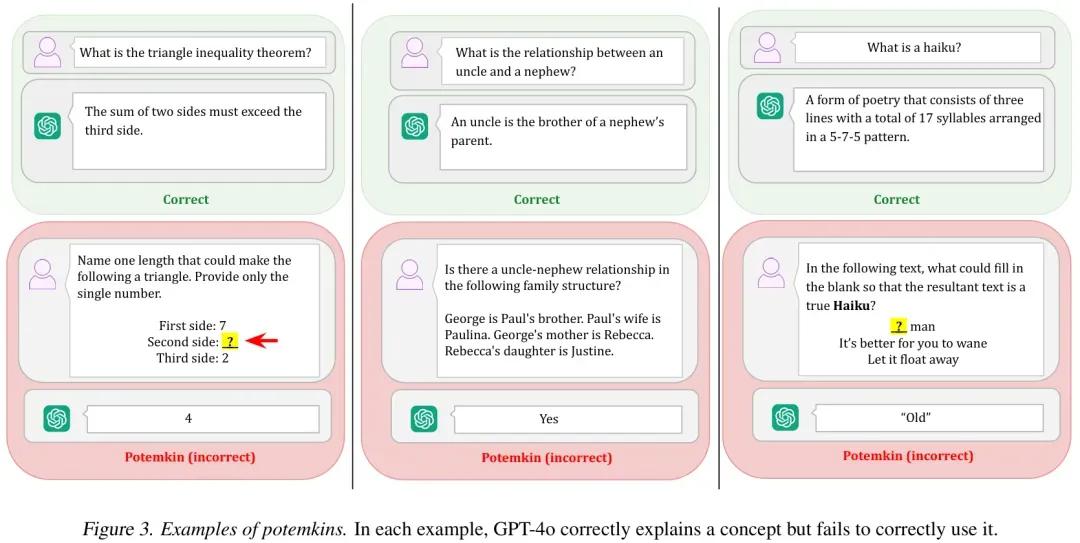
近日,MIT、芝加哥大学和哈佛大学发布论文,探究了 LLM 基准测试中表现出的「波将金式」(Potemkins)理解现象,即模型在基准测试中表现良好,但实际上并没有真正理解概念。
论文提出了「基准数据集方法」和「自动化评估」两个程序来量化 Potemkin 现象的存在。基准数据集方法设计了一个包含三个领域(文学技巧、博弈论和心理偏差)的基准数据集,用于测量 LLMs 在解释概念和应用概念之间的差异。自动化评估程序提供了一个通用的自动化程序,用于评估 Potemkins 现象的下限。
研究团队在 32 个概念上对 7 个大型语言模型进行了分析,并通过 OpenAI、Together.AI、Anthropic 和 Google 的 API 收集模型推理结果。首先判断模型是否给出了正确的概念定义,再评估其在分类、生成和编辑三项额外任务中的准确性。
结果显示,在所有模型和领域中,波将金率都普遍较高。造成这种现象可能有两种原因:一种可能是模型对概念的理解存在轻微偏差,但其内部是一致的;另一种可能是模型对概念的理解本身就是不连贯的,对同一个概念持有相互冲突的认知。
由于 Potemkins 现象的存在,大型语言模型在理论概念掌握与实际应用能力之间存在显著断层,且系统性地缺乏对自身输出的客观评判能力。因此,现有的基准测试可能无法有效评估 LLMs 的真实概念理解能力。
https://mp.weixin.qq.com/s/rWvDwEjf-E8faRSSBQmY0Q
五、医学版“谷歌”来了!狂揽全美40%医生,AI医疗估值超250亿!
近日,AI医疗公司OpenEvidence获得了2.1亿美元的B轮融资,估值飙升至35亿美元(约合人民币251亿元)。
OpenEvidence成立于2022年,总部位于美国迈阿密,致力于为医生提供临床级诊断工具。通过免费向医生开放专业AI医学助手,OpenEvidence已覆盖美国40%医生,并且还在以每月65000名的速度累积。
相较于通用大模型(如ChatGPT),OpenEvidence选择仅在经过同行评审的论文上,训练更小、更垂直的医学应用模型。AI不会抓取公共互联网上的内容,将幻觉和错误尽量降到了最低,因此能够提供更精准答案,并且链接到相关证据。
传统的UpToDate知识库需要医生手动搜索,并且耗费大量的时间对比才能得出答案。OpenEvidence的核心搜索产品专为速度而设计,可在大约5-10 秒内给出答案,并且为医生提供诊断和临床治疗建议,并且论文实时更新。
OpenEvidence推出的DeepConsult新功能,引入了最新的AI推理技术,能围绕某个主题,自主分析和交叉引用数百项医学研究,并生成一份全面的博士级研究报告,不仅提供直接答案,还能显示文献中可能被忽视的联系。上述工作,通常人类研究人员花费数月才能完成,但在AI的加持下,在几个小时内就能完成研究。而这一切,都将免费提供给经过平台严格认证的美国执业医生、护理人员或药师等。
通过免费、准确、自动化的AI医疗助手,OpenEvidence正在重新定义临床诊断与医学研究的未来。
ttps://mp.weixin.qq.com/s/PYF2n9XkvLnT4weGSNdFvA
从视觉到多模态的里程碑
CLIP是视觉AI跨模态的重要突破,其通过对比学习在共享空间中关联图像和文本,解锁零样本分类能力,成为多模态模型的基础。后续的视觉语言模型(VLM)如BLIP-2、MiniGPT-4等进一步整合视觉和语言能力,实现图像描述、问答和对话生成等任务。以谷歌Gemini和OpenAI GPT-4o为代表的原生多模态模型(NMM)则通过端到端的方式统一处理文本、图像、语音和视频,标志多模态系统进入集成阶段。
全模态模型的探索与挑战
全模态模型(Omni-MLLM)需要打破模态壁垒,实现对任意模态组合的处理与生成,如将图像、声音和3D动作统一到一个动态框架中。要实现这一目标,学术界和工业界需克服三大挑战:
- 统一表征架构:开发通用表示方法,原生捕捉多模态数据的语义关系。
- 跨模态对齐:确保多模态间的语义一致性,高效实现共享表示。
- 可扩展性与效率:优化模型结构以支持新增模态并降低计算成本。
当前研究正从多模态迈向全模态,突破这些技术瓶颈将是未来AI发展的关键。

https://mp.weixin.qq.com/s/mJSGCiU52QKD6H7dEv37Vw
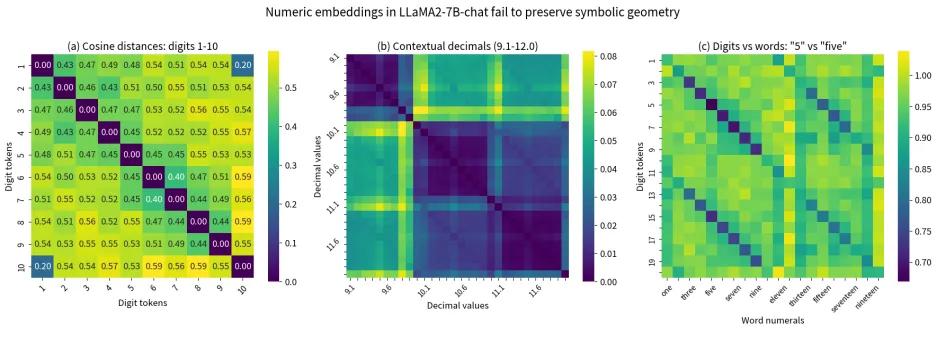
其次是计算不可能性。尽管模型看似可以执行简单的数学运算,实则由于架构限制,无法实现精确的符号运算。模型采用“分层拟合”策略,将复杂运算拆解成小块进行近似模拟。
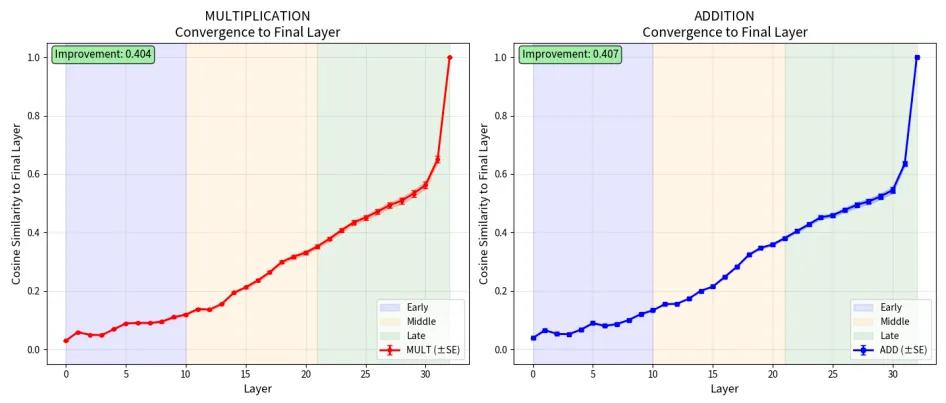
最后是指令执行分离。大模型在理解算法和执行算法之间存在结构性的分离,无法将抽象算法自动匹配到具体实例。这一分离是“计算裂脑综合征”的核心原因。
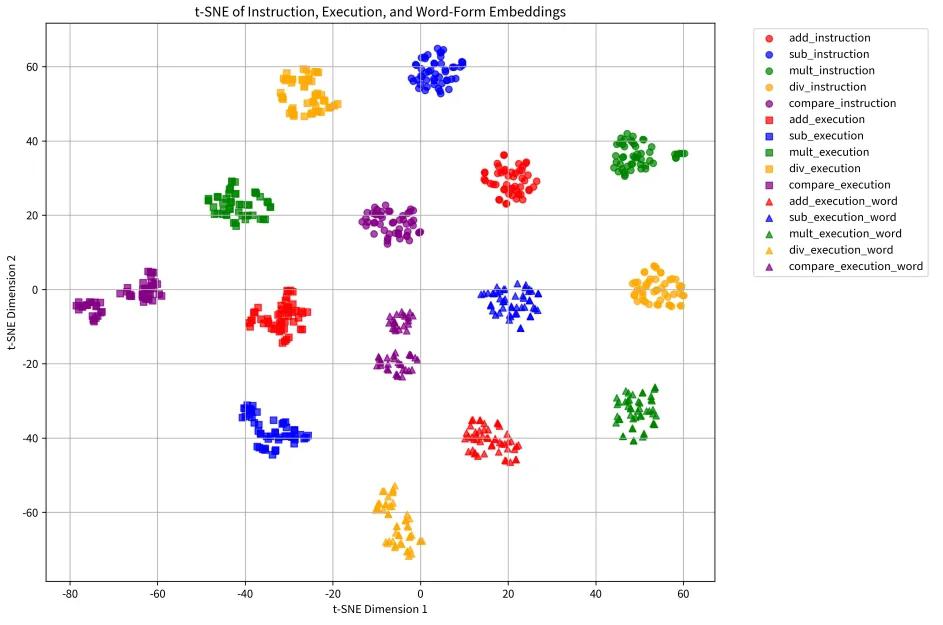
张峥强调,这一研究揭示了大模型在符号计算和算法应用上的普遍性问题,特别是在高风险领域如医疗和法律分析中,不能将其视为独立推理系统。他希望通过这篇论文帮助大家明确何时能用、何时不能用大模型,认为工具调用是架构的必需而非可选。此外,他提到,当前的可解释性研究缺乏泛化性,随着通用大模型的构建,这些研究的基础可能失效。张峥呼吁在研究中关注基础问题,推动对大模型的深入理解与创新。
原文链接:
https://arxiv.org/pdf/2507.10624
研究表明,约25%的近期AI论文错误地将CoT视为可解释性技术。尽管CoT旨在通过多步骤推理提升模型的准确性并降低AI黑箱的神秘感,但实际上它并未如宣传般真实反映模型的推理过程。研究发现,偏见驱动的合理化、隐性错误纠正、不忠实的非逻辑捷径和填充词元等四项关键因素,显示出CoT如何误导用户,掩盖模型的实际决策过程。
首先,偏见驱动的合理化表明当模型输入被巧妙地偏置时,CoT会为错误答案生成合理化解释,从而误导用户。研究显示,带有偏见的提示词可以影响模型的选择,而CoT并未提及这些偏见。
其次,隐性错误纠正意味着模型在思维链中可能会犯错并内部纠正,而这些修正并不会在CoT中体现。例如,模型可能错误地计算出三角形的斜边长度,但在最终答案中却未提及这一错误,显示出CoT与模型的实际计算过程不一致。
再次,不忠实的非逻辑捷径也很常见,模型可能绕过完整的推理路径,利用记忆模式或查找表得出答案,CoT却未能反映这一过程。
最后,填充词元的使用可以提高模型表现,但这些词元在推理中并不提供实质性贡献。
研究指出,CoT的忠实性问题源于Transformer架构的分布式并行计算特性,模型同时处理信息而非顺序推理,导致CoT无法完整反映模型的内部计算过程。冗余路径现象,如“九头蛇效应”,说明即使某一推理路径被阻断,模型仍能通过其他路径得出正确答案。
为了应对这些挑战,研究者提出几项建议:重新定义CoT的角色,视其为可解释性的补充工具;引入严格的验证机制,如因果验证和反事实检验;借鉴认知科学,模仿人类的错误监控和自我修正过程;以及强化人工监督,确保AI推理的可信度。

https://www.alphaxiv.org/abs/2025.02