
AI Industry-Academia Insights
AI行业资讯专家精选No.20:LeCun实现16秒连贯场景预测,Meta发布世界模型V-JEPA2,微软提出强化学习预训练方法
发表日期: 2025年7月16日
一、LeCun发布最新世界模型:首次实现16秒连贯场景预测,具身智能掌握第一视角!
6月26日,LeCun团队发布了PEVA模型,让具身智能体不再依赖“上下左右”这种抽象信号进行训练,而是以第一人称视角的视频+全身姿态轨迹为输入,让它“模仿”人类第一视角下的动作与感知。通过随机时间跳跃与跨历史帧注意力,解决了扩散模型在长时序动作预测中的计算效率与延迟效应问题。不仅能让智能体精确模拟伸手取物、行走转向等基础动作,更实现了长达16秒的连贯场景预测。
PEVA模型:像人类一样“模拟”世界
LeCun团队认为具身智能体世界模型应具备理解、预测和规划等能力,能够让机器像人一样“想象”动作后的视觉效果。于是,PEVA模型摒弃了抽象控制信号,采用真实物理基础上的复杂动作空间。其关键创新在于用全身动作数据训练模型,让智能体在多样化的现实场景中以第一人称视角行动。
实验成果:从“机械执行”到“智能规划”的跨越
PEVA模型让具身智能体实现了从人体关节运动学轨迹到第一人称视频的端到端预测。在单步预测中,相比CDiT基线模型,PEVA的LPIPS值降低0.01,FID降低1.42,表明其生成画面与真实画面的视觉相似度更高、生成质量更优。长视频生成方面,在16秒长序列预测时,PEVA的FID值相比DiffusionForcing(DF)低15%以上,生成视频的时序连贯性显著增强。

https://arxiv.org/abs/2506.21552
6月11日,Meta推出基于视频训练的世界模型V-JEPA2(全称VideoJointEmbeddingPredictiveArchitecture2),能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。目前,V-JEPA2在HuggingFace关于物理推理榜单上排名第一,超越GPT-4o等。
V-JEPA2是在JEPA的基础上构建的视频模型,主要包括编码器和预测器两个核心组件。编码器负责接收原始视频数据并将其转化为视频嵌入表示,而预测器则基于视频嵌入和额外的上下文信息,输出对未来内容的预测嵌入。在训练过程中,Meta采用基于视频的自监督学习方法,无需额外人工标注即可实现对V-JEPA2模型的有效训练。在预训练阶段,Meta使用了超过100万小时的视频数据及100万张图像。在第二阶段训练中,仅使用62小时的机器人交互数据,Meta就能够成功建立一个适用于机器人规划与控制的高效模型。
此外,Meta还发布了三个新的测试基准,用于评估现有模型从视频中理解和推理物理世界的能力。测试表明,在预测物理世界在给定动作和事件空间的情况下可能如何演变方面,包括V-JEPA2在内的顶级模型与人类表现之间仍存在显著差距。下一步,Meta计划在多个领域进一步探索世界模型,希望专注于训练能够跨多个时间和空间尺度进行学习、推理和规划的分层JEPA模型。

6月9日,微软、北京大学和清华大学的研究者提出强化预训练方法(ReinforcementPre-Training,RPT),通过强化学习训练模型在预测下一个token前进行显式推理,提升大语言模型的推理能力和语言建模性能。
RPT将传统的对next-token的预测任务重构为对next-token的推理过程:对于预训练语料中的任意上下文,模型需在预测前对后续Token进行推理,并通过与语料真实的next-token比对获得可验证的内在奖励。该方法无需外部标注或领域特定奖励函数,即可将传统用于next-token预测的海量无标注文本数据,转化为适用于通用强化学习的大规模训练资源。通过OmniMATH数据集(包含4428个竞赛级数学问题和解答)强化预训练发现:
- 在语言建模提升上,RPT-14B模型在下一个token预测任务中准确率超越了基线模型(如DeepSeek-R1-Distill-Qwen-14B),性能接近更大规模模型(32B)。
- 在Scaling特性上,随着计算量增加,RPT的预测准确率也在持续提升。
- 在下游任务迁移中,经RPT预训练的模型在强化微调(RLVR)中表现更优,推理能力显著增强。
- 在零样本性能中,RPT-14B在多项基准测试中超越同规模模型,部分指标优于更大模型。
RPT范式的好处在于,它提供了一种可扩展的方法,能够利用海量文本数据进行通用强化学习,而无需依赖特定领域的标注答案。通过激励模型进行下一个token的推理,RPT显著提升了next token prediction的语言建模准确性。此外,RPT为后续的强化微调提供了一个强大的预训练基础。

https://www.arxiv.org/pdf/2506.08007
四、WorldLabs开源Forge渲染器
6月3日,李飞飞空间智能创业公司WorldLabs开源Forge渲染器,可实现在桌面端、低功耗移动设备、XR等所有设备上实时渲染AI生成的3D世界。
Forge是一款Web端3D高斯泼溅渲染器,集成了three.js,可实现完全动态和可编程的高斯泼溅。其底层为GPU优化设计,地位相当于传统3D图形领域的基础组件“着色器”。Forge只需极少的代码即可启动和运行,支持多个splat对象、多个摄像头以及实时动画/编辑。此外,它允许将函数块(称为Dyno)组合成计算图形,可以程序化地生成、任意修改Spalt,或执行能想到的任何其他计算,并转换为GLSL语言在GPU上运行。
Forge系统设计的核心在于对每个splat进行排序管理,其中关键组件是ForgeRenderer。ForgeRenderer负责遍历并编译Three.js场景中所有的splat,形成一个完整的列表。每个ForgeRenderer实例均配备一个默认的ForgeViewpoint,该视角从GPU读取所有splat信息,并利用桶排序(Bucket Sort)算法确定splat的绘制顺序。这一排序过程由SplatWorker在后台工作线程中高效执行。此外,Forge还允许用户定义可编程的数据流水线,这些流水线在GPU上针对每个splat并行运行。
在此过程中,Forge也支持完全控制编写任何以编程方式计算splat属性(中心、比例、四元数、RGBA)的函数。其属性可以是无状态的,也可以依赖于splat文件、纹理和其他全局参数的复杂组合进行实时程序生成,可以随时间变化以生成实时动画。
https://mp.weixin.qq.com/s/rUtF0BIGxUZxR65h5ZzAGQ
五、Nature | 应用于胸部X光的开源AI基础模型
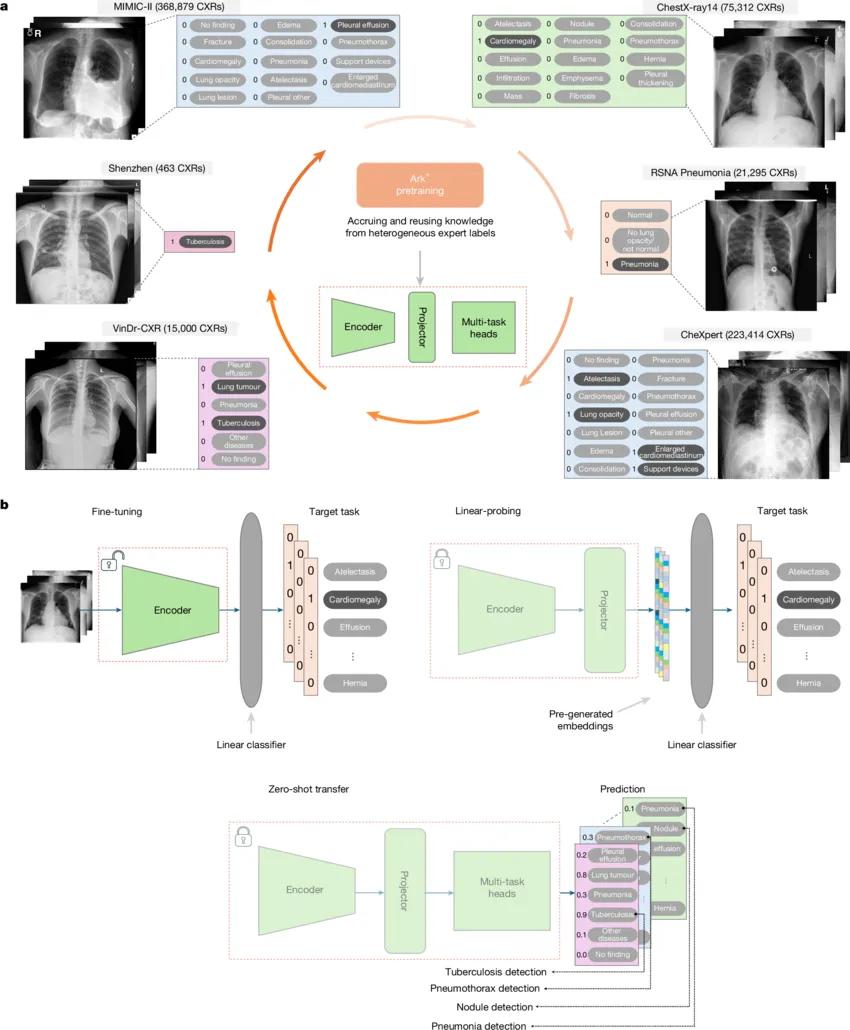
6月11日,一篇应用于胸部X光的开源AI基础模型Ark+在Nature正刊发表。该模型以跨数据集的专家标签为基础,预训练过程通过循环式学习方式整合并复用异构知识,旨在解决现有模型在诊断范围、泛化性、适应性、稳健性和可扩展性方面的局限。
Ark+模型的所有训练数据都来自6个公共数据集的704,363张胸部X光片,包括:ChestX-ray14、CheXpert、MIMIC-CXR、RSNAPneumonia、VinDr-CXR、ShenzhenCXR。Ark+在八种典型临床场景下展示强大能力:
- 诊断常见疾病:平均AUC84.43%,优于CXR-FM、RAD-DINO等;
- 适应标签变更:未见局灶标签也能迁移学习,体现泛化能力;
- 少样本学习:在仅1–5个样本下完成罕见病检测;
- 长尾任务:对小样本类别的识别优于所有对比模型;
- 零样本迁移:直接推理新中心数据,AUC可达97.6%;
- 抗性别偏倚:性别分布不均下仍保持性能稳定;
- 新疾病(COVID-19)适配:支持增量预训练,迅速适应新病种;
- 联邦学习扩展:可用于隐私敏感场景,保护患者数据。
Ark+通过整合多数据集专家知识,以开源形式实现了优异的胸部疾病诊断性能。其开放性使得模型具备持续更新、低成本适应新任务的能力,在实际应用中能快速响应疾病谱变化(如COVID-19),同时能保护患者隐私(通过联邦学习)并缓解性别偏倚。此外,Ark+支持从分类扩展到定位和分割任务,具备高度的可扩展性。
https://www.nature.com/articles/s41586-025-09079-8
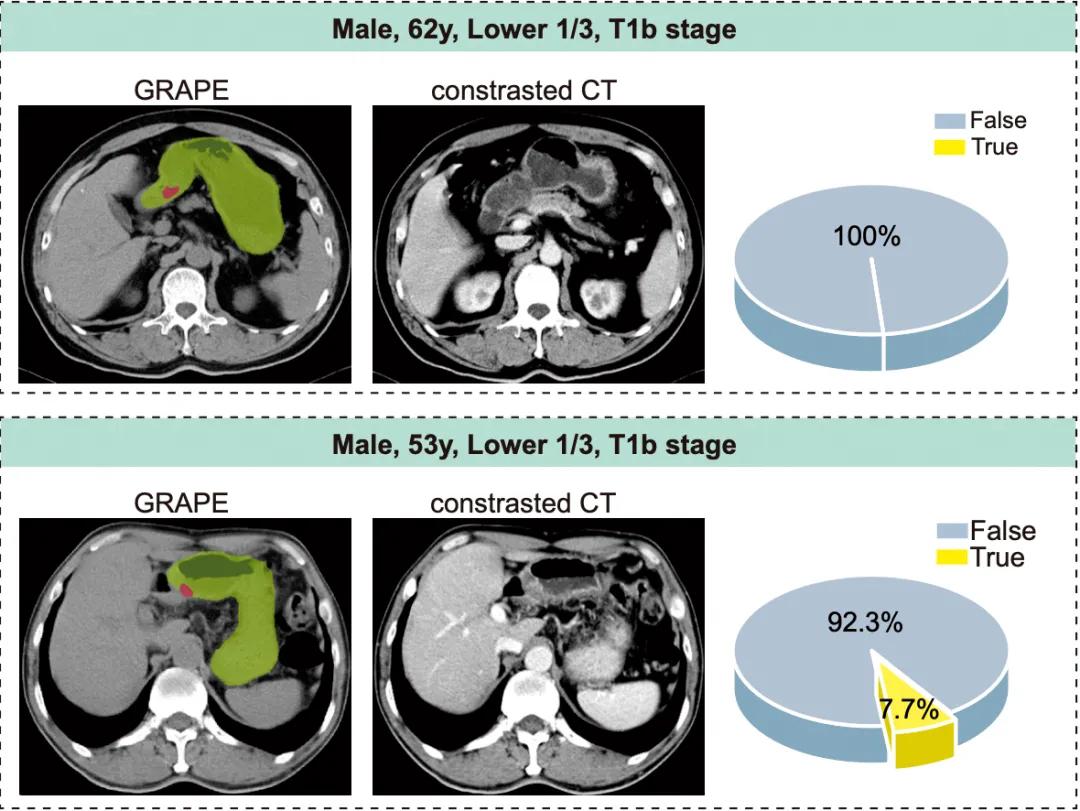
6月24日,阿里巴巴达摩院的医疗AI团队在国际医学顶级期刊Nature Medicine发表了一项最新研究,报告了只需平扫CT即可检测胃癌早期病变的医疗AI模型GRAPE(Gastric Cancer Risk Assessment Procedure with Artificial Intelligence)。
GRAPE胃癌风险评估人工智能大模型,联合来自中国的东部、东北、西北、华南等地的20个医疗中心,开展覆盖近10万人的回顾性临床试验。经过两万多例训练与验证后,GRAPE在浙江两家地区医院的模拟机会性筛查试验中,识别出高危人群,后续的胃镜检查显示,其中胃癌患者的比例分别达到了24.5%和17.7%。
这巧妙地避开了全人群胃癌筛查对大量医疗资源的占用,为胃癌的早期筛查和诊断开辟了一条全新的道路。这种新技术的加持有望在未来显著改善胃癌患者的预后,降低胃癌相关的死亡率,成为中国乃至全球胃癌防控领域的一把利刃。目前,浙江省肿瘤医院已经在PACS系统本地部署GRAPE模型,对前来医院各科就诊患者的每天产生的近千张平扫CT影像,AI持续自动检测、随时报警。
https://mp.weixin.qq.com/s/Z-ufMQ9Cdw3NZehIwPFSfw?scene=1
6月10日,a16z发布了2025年度的「企业如何采购AI」主题报告,该报告基于对全球企业高管的深度访谈与广泛调研,揭示了2025年企业在以LLM为代表的生成式AI的采购、部署与预算分配上的关键趋势。
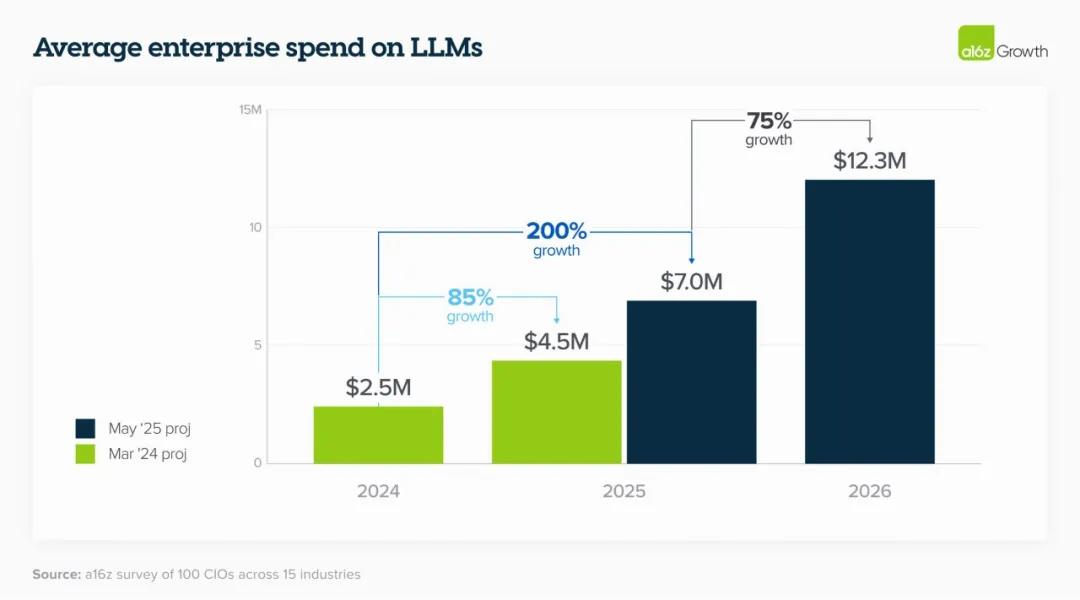
为何企业的AI预算只增不减?
a16z的研究组发现,得益于2023年企业在部署AI(LLM)方面支出所收获的积极成果,企业的AI预算在2024年和2025年度持续增长,且涨幅超出预期。越来越多的企业不再以试点项目的形式部署AI,而是以核心IT业务的需求驱动,将永久性预算用作AI的采买。在证明AI对业务运营的重要性后,企业将开始构建面向用户的AI服务,进而促使AI支出大幅增加。
货比三家,什么样的LLM能让企业掏钱?
伴随市面上高性能LLM的增多,企业作为购买者往往会在生产流程中部署多个模型。虽然不同的模型在某些层面于通用评估中表现相似,但这些模型各自在代码完善、系统设计、文本生成等任务的能力优势让企业倾向采用多个模型来构建最佳实践。OpenAI仍保持领先的市场份额,但谷歌和Anthropic的市场接受度在过去一年中取得了长足的进步。此外,2025年的调查发现企业对开源模型的采用也在增多。
企业如何像采购传统软件一样采购AI模型?
2025年的调查发现,企业越来越多地选择直接与模型提供商合作,或通过平台(如Databricks)托管,以直接获取最新、性能最佳的模型。在采购过程中,虽然内部基准测试、黄金数据集和开发者反馈仍然是更深入评估LLM性能的关键部分,但LLM市场的成熟促使公司越来越多地参考LMArena等外部基准测试。
https://a16z.com/ai-enterprise-2025