
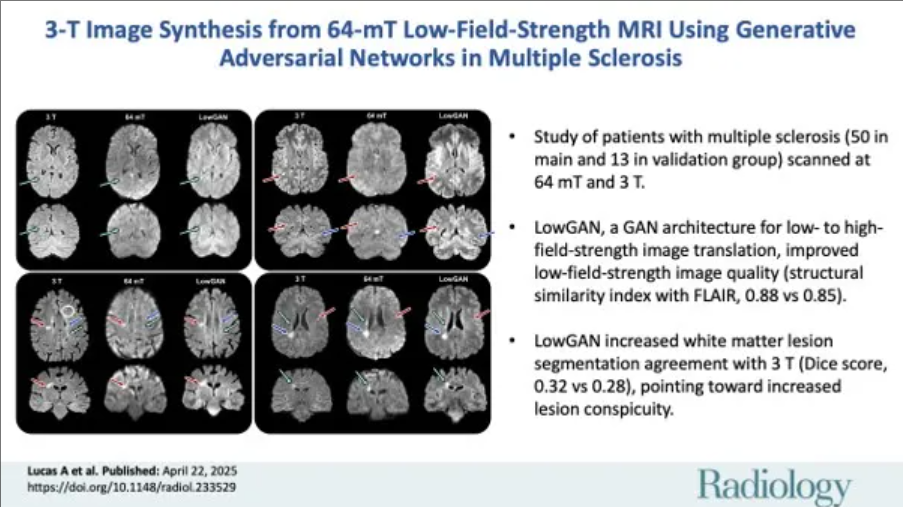
AI Industry-Academia Insights
AI行业资讯专家精选No.19: 预训练之后,What to Scale Now? LowGAN让64mT图像质量直追3T
发表日期: 2025年6月13日
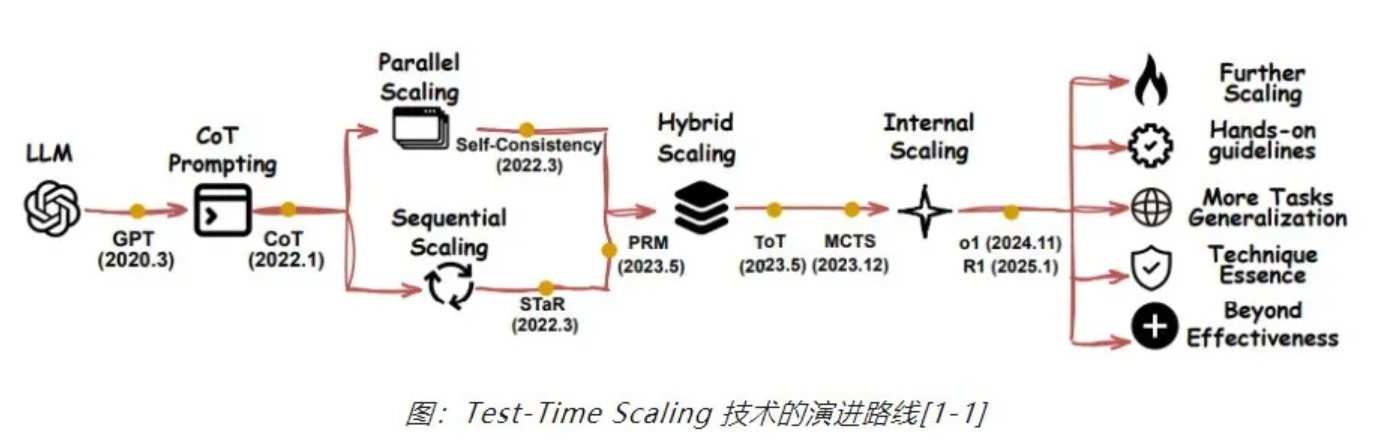
探索新的 Scaling 目标
自2024年起,随着预训练环节Scaling Law的边际效益递减,业界开始探索新的Scaling 路径,进而衍生出有关「Self-Play RL+ LLM 」、「Post-Training Scaling Law」、「Test-Time Training」等路线。其中,Test-Time Scaling(TTS)逐渐成为研究重点,其通过在推理阶段增加计算资源来增强模型性能,从简单的重复采样发展到复杂的混合扩展和内部扩展策略,应用范围也从特定领域扩展到通用任务。
微调与推理的同等重要性
传统观点认为预训练奠定模型基础能力,微调则是关键一步。然而,随着 LLM的广泛部署,推理阶段的重要性日益凸显。推理策略设计得当的模型,即使基础能力并非顶尖,也能通过「聪明」的推理过程弥补不足。因此,后训练的 Scaling Law不再仅关注微调阶段,而是转向一个更综合的框架,量化微调计算量、微调数据量、推理计算量与模型性能之间的关系,解决在既定计算预算下如何分配资源以实现性能最大化的问题。
Scaling Law 的多领域应用
Scaling Law的影响力和应用范围超出了LLM的范畴。2025 年,UT、清华和佐治亚理工等机构提出「自主通才科学家」(AGS)概念,指出科学发现可能遵循全新的扩展定律。AGS系统通过自动化流程加速科学发现,减少对专业知识的依赖。谷歌提出了面向DiLoCo分布式训练方法的Scaling Law,发现其在模型规模增大时性能提升更为明显。苹果与牛津大学提出了蒸馏扩展定律,可基于计算预算及其在学生和教师模型之间的分配估算蒸馏模型的性能,为知识蒸馏技术提供了理论支持。

四、谷歌DeepMind提出进化编码Agent「AlphaEvolve」
近日,谷歌DeepMind与陶哲轩等科学家近期发布论文,提出了基于LLM的进化编码Agent「AlphaEvolve」,用于通用算法的发现与优化。AlphaEvolve是一个LLM驱动的进化编码Agent,通过一个自主的LLM流程来改进算法,直接对代码进行修改,并利用进化方法,持续从一个或多个评估器接收反馈,迭代地改进算法。其工作流程包括人类定义“是什么”,即设置评估标准、提供初始解决方案和可选的背景知识;而AlphaEvolve则解决“怎么做”,通过迭代改进解决方案。
AlphaEvolve在谷歌内部的应用成果较好,在数据中心调度上,该工作提出的解决方案已投入生产超过一年,平均持续恢复谷歌全球0.7%的计算资源;在协调硬件设计上,该工作提出Verilog重写方案,删除了矩阵乘法关键算术电路中高度优化的、不必要的位;在AI训练和推理上,该工作通过找到将大型矩阵乘法运算划分为更易于管理的子问题的更智能方法,将Gemini架构中的大型矩阵乘法运算加速了23%,缩短训练时间了1%;在数学和算法上,该工作设计了基于梯度的新型优化程序的诸多组件,发现了一种使用48次标量乘法来对4x4复值矩阵进行乘法运算的算法,改进了Strassen于1969年提出的算法。
研究团队对多个 LLM 在 BBEH 上的表现进行了详细测试。结果显示,当前最强的推理专用模型(OpenAI o3-mini)也仅达到 44.8% 的准确率。这一结果清晰地表明,在推理能力方面,LLM 仍存在巨大提升空间,尤其是在处理复杂、多样化的任务时。BBEH 的发布不仅为评估 LLM 的推理能力提供了更高的标准,也为未来模型的优化和多样化能力提升指明了方向。随着这一新基准的应用,我们有望见证更智能、更强大的 AI 模型的进一步发展,从而更好地服务于科学研究、技术创新及社会需求。
 原文链接:
原文链接:五、苹果开源视觉语言模型FastVLM
苹果开源了一个能在iPhone上直接运行的高效视觉语言模型——FastVLM(Fast Vision Language Model)。
视觉语言模型(VLMs)在处理高分辨率图像时,面临传统视觉编码器(如ViT)在高分辨率下效率低下的问题,且生成的视觉token过多,导致语言模型(LLM)预填充时间增长,首次输出时间(TTFT)变长。
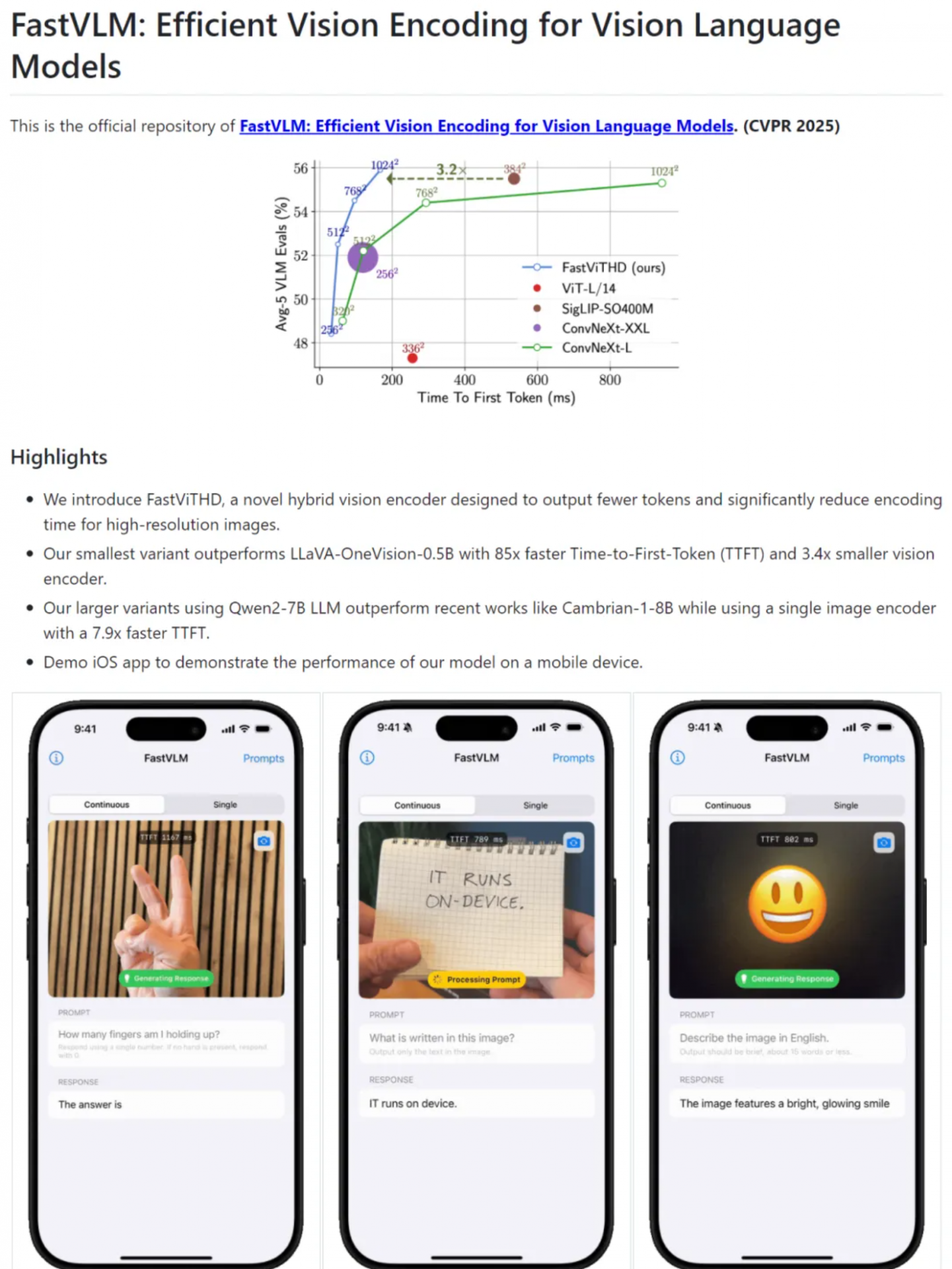
为解决上述问题,研究者提出了FastVLM方法,引入了混合视觉编码器FastViTHD,以高效处理高分辨率图像,从而提升VLMs的整体性能。FastViTHD通过多尺度特征提取和池化策略,以及额外的自注意力层和下采样操作,生成比传统ViT模型少得多的视觉token(比传统ViT少16倍,比FastViT少4倍),从而减少编码时间和LLM的预填充时间。FastVLM可以用于模型自动生成陈述,同时兼容主流LLM并适配iOS/Mac生态,适合边缘设备、端侧AI应用和实时图文任务场景的落地。
经测试,对于广泛使用的多模态大模型LLaVA-1.5,FastVLM在生成首token(TTFT)的速度比以往的工作快3.2倍,同时在VLM基准测试中保持了几乎相同的性能。在最高分辨率(1152×1152)下,FastVLM使用相同的0.5B语言模型,在关键基准测试(如SeedBench和MMMU)上实现了与LLaVa-OneVision相当的性能,但TTFT快了85倍,视觉编码器的大小也缩小了3.4倍。
在内镜黏膜下剥离术中,精确且直观地感知目标组织是提高手术精度的关键。增强现实(Augmented Reality,AR)技术为手术提供了直观的引导方案。
近日,香港中文大学任洪亮教授团队提出了一种针对可变形组织的自动校准与动态注册方法,可以进一步优化手术中的引导效果。首先,该方法设计了一种基于6D位姿估计器的自动校准策略,用于将虚拟世界中的目标组织与现实世界无缝对齐,通过结合特征匹配网络SuperGlue和深度估计网络Metric3D,实现高效且稳定的虚实结合。其次,为了实时跟踪目标组织的变形情况,该方法提出了一种动态注册策略,可以实时捕捉组织形变,从而在手术中提供更加可靠的引导。
在以猪小肠组织为实验对象进行的离体实验结果显示,该方法AR校准的平均绝对误差(MAE)为3.11±0.56mm,动态注册误差的MAE为3.20±1.96mm。
