
Highlights & News
CAIR在人工智能国际顶级会议发表多项学术研究成果
发表日期: 2025年4月30日
中国科学院香港创新研究院人工智能与机器人创新中心 (CAIR) 团队近期发表多篇论文,其中两篇论文分别被AAAI人工智能会议(AAAI 2025)与国际顶级会议国际计算机视觉与模式识别会议(CVPR)接收!
论文一:
AAAI 2025 | Pareto Continual Learning: Preference-Conditioned Learning and Adaption for Dynamic Stability-Plasticity Trade-off
论文作者:
Song Lai, Zhe Zhao, Fei Zhu, Xi Lin, Qingfu Zhang, Gaofeng Meng
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/33981
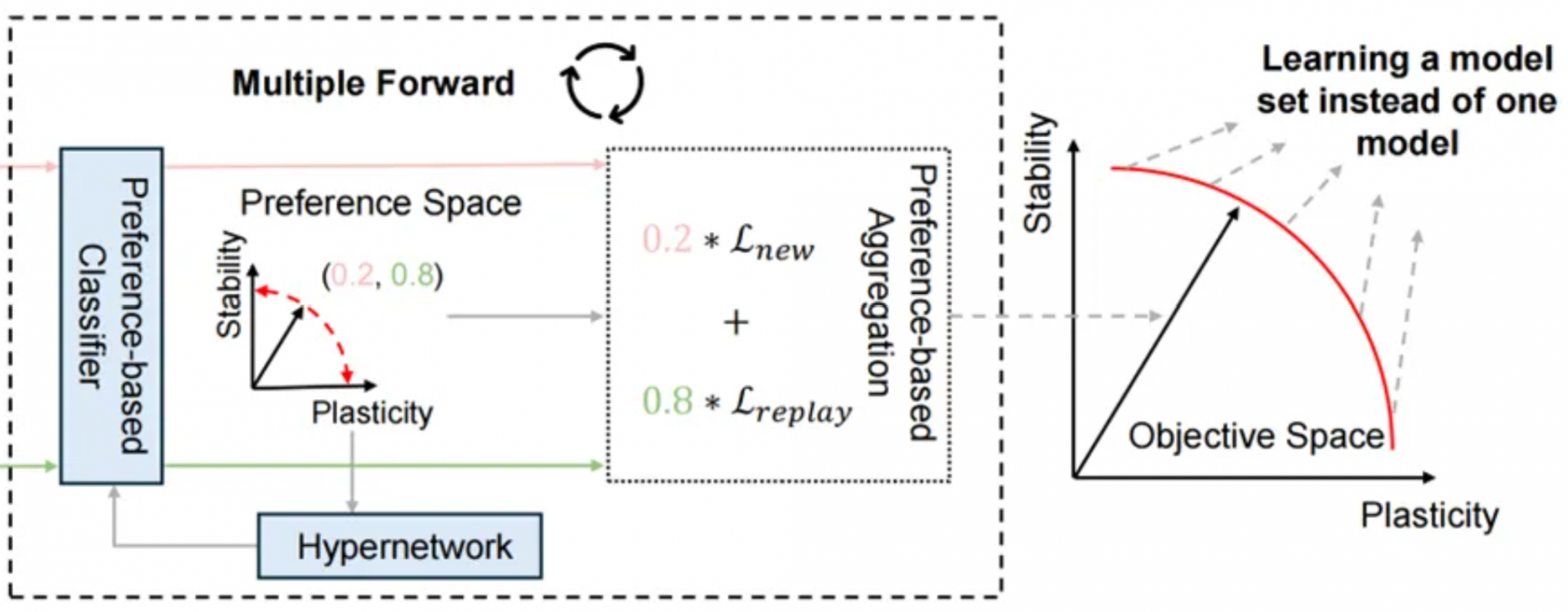
连续学习旨在让智能体像人类一样,在动态环境中不断学习新任务而不遗忘旧知识。然而,现有方法通常采用固定的权衡策略来平衡“稳定性”(保留旧知识)和“可塑性”(学习新任务),无法根据任务需要灵活调整策略。这种固定的策略导致模型在复杂场景中难以兼顾历史知识与新任务需求,限制其实际应用的潜力。
为了解决这个问题,我们提出帕累托连续学习(ParetoCL),首次将多目标优化引入连续学习领域,将稳定性和可塑性的冲突建模为动态权衡问题。训练时,模型随机组合不同偏好学习帕累托最优解集;推理时,根据输入样本自动选择最合适的策略偏好。ParetoCL突破传统固定权衡的局限,在学习和推理中实时调整策略,在各类基准数据集上将平均性能提升超10%,同时仅需单模型即可覆盖多种权衡策略,计算成本仅为基准方法的四分之一。ParetoCL为连续学习提供了新范式,是对困扰领域多年的稳定性-可塑性冲突难题的一次尝试,开创了多目标优化与连续学习结合的新方向。其动态适应特性在机器人交互、医疗诊断等需实时调整的场景中潜力巨大,例如让手术机器人根据临床需要既能快速学习新病例,又能基于历史经验进行泛化,提升操作安全性。
论文二:
USPilot: An Embodied Robotic Assistant Ultrasound System with Large Language Model Enhanced Graph Planner
论文作者:
Mingcong Chen, Siqi Fan, Guanglin Cao, Hongbin Liu
论文链接:
https://arxiv.org/abs/2502.12498
近年来,大语言模型的快速发展,让人工智能具备了理解复杂语言指令和自主决策的能力。这种技术的进步为医疗机器人,尤其是全自动超声机器人带来了新的潜力。超声检查因其实时成像和无辐射的特点,在医疗诊断中被广泛使用。然而,全球专业超声医生短缺,且超声操作对医生的体力和技能要求较高,导致效率和普及受到限制。全自动超声机器人借助大语言模型的技术突破,有望解决这些问题,推动医疗自动化的实现。
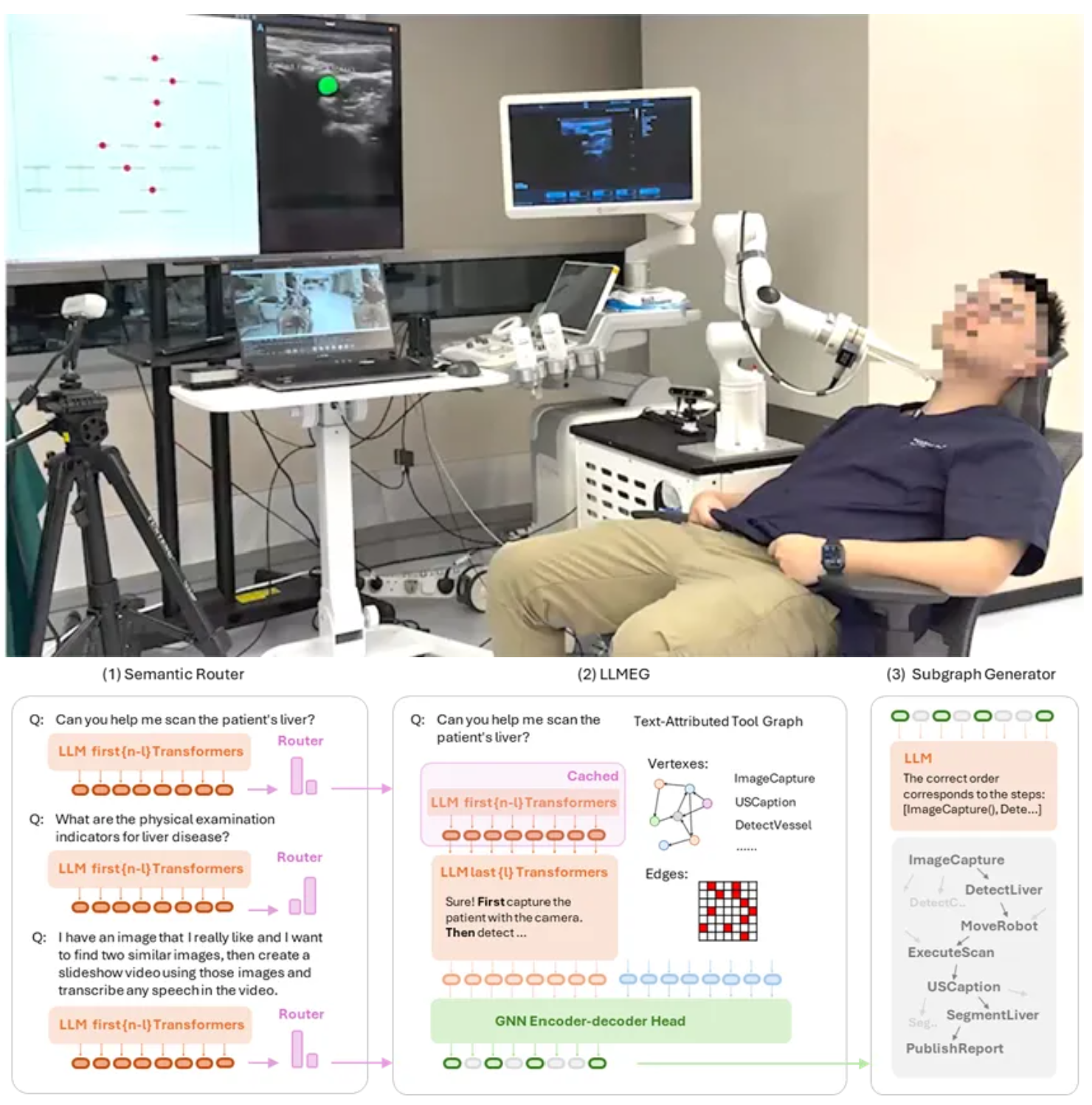
我们研发了USPilot超声机器人系统,它融合了大语言模型(LLM)和图神经网络(GNN)技术,能够像“虚拟医生”一样与患者互动,并自主完成超声检查。USPilot通过大语言模型理解患者的自然语言指令,例如“我的体检报告提示转氨酶过高,可以帮我检查一下吗”,自动生成机器人对应部位的操作步骤,完成精准扫描。系统利用图神经网络进行任务分解和规划,自动选择合适的操作工具和执行路径,确保任务高效完成。USPilot通过轻量化适配技术,能不断学习和更新超声检查相关知识,适应不同的患者需求和检查场景。
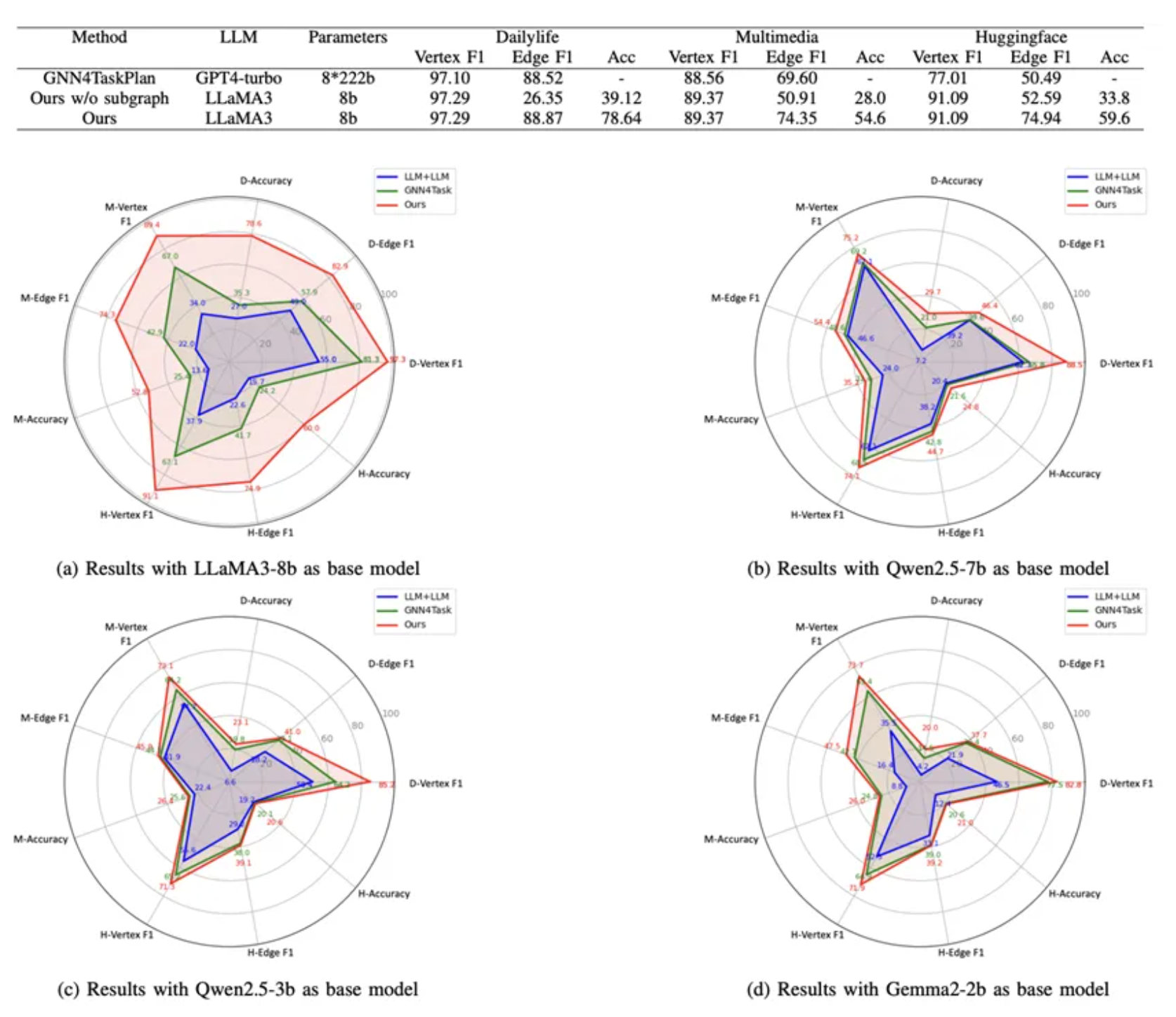
与传统超声机器人相比,USPilot不需要人工编程调试,医生只需用自然语言与系统互动即可开展工作,显著降低了操作门槛。USPilot系统的LLM增强图神经网络在开源数据集上的表现十分出色。在Dailylife、Multimedia和HuggingFace三个数据集上,LLMEG均优于对比方法,即使后者使用了参数规模更大的GPT-4-turbo模型(8个222B参数专家模型)。在Dailylife数据集中,LLMEG的节点(vertex)和边(edge)F1得分分别为97.29%和88.87%,略高于GNN4Task(97.10%和88.52%)。在Multimedia数据集上,LLMEG的节点和边F1得分分别提高了0.81%和4.75%。在专业性更强的HuggingFace数据集中,LLMEG对节点选择和边预测的提升分别达到了14.8%和24.45%。与使用传统深度优先搜索(DFS)方法相比,LLMEG通过语义增强的子图规划使边F1分数提升了22.4%~62%,总准确率提高25.8%~39.52%,尤其在复杂图结构中效果更为显著。在相同基座模型llama3-8b下任务规划准确率提升了25%以上,体现了其在理解复杂任务逻辑和高效执行方面的卓越能力。保证了操作的安全性和精准性。
USPilot是全球首个将大语言模型与图神经网络结合用于超声检查的机器人系统,实现了医疗机器人从“被动工具”向“智能助手”的转变。这一突破不仅能缓解超声医生短缺的问题,还为未来实现无人化医疗影像技术提供了坚实的技术基础。
论文三:
CVPR 2025 | Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
论文作者:
Zhiyuan Ma, Xinyue Liang, Rongyuan Wu, Xiangyu Zhu, Zhen Lei, Lei Zhang
论文链接:
https://github.com/theEricMa/TriplaneTurbo
现有的文本到3D生成技术面临三重挑战:第一,效率低,传统方法(如DreamFusion)需逐样本优化数小时,依赖人工调参;第二,数据荒,数据驱动模型依赖小规模3D数据集(如Objaverse仅数百万样本),难以生成复杂概念(如“机械恐龙”),且数据存在纹理粗糙、姿态混乱问题;第三,多视角重建难,现有方法需先生成多视角图像再重建3D网格,耗时长(数分钟)且易出现结构错误。这些问题导致3D生成技术难以满足影视、游戏等实时创作需求。
因此,研究团队提出了TriplaneTurbo方案,将文生图模型Stable Diffusion(SD)改造为“3D翻译引擎”,通过以下创新解决上述问题:
多教师协同指导:
让多个文生图模型分别充当“文本翻译官”,“视角协调员”和“几何质检员”,通过2D图像反馈联合训练,无需任何3D数据。
四步极速生成:
将SD生成图片的“去噪”过程转化为三维空间构建:从噪声中逐步生成3D模型的“骨架”(Triplane),仅需1.2秒输出带纹理的网格文件。
轻量级3D解码器:
设计微型适配模块(PETA),仅调整SD 2.5%参数,保留其对复杂文本的理解能力。
TriplaneTurbo具有三大优势:第一,质量高,CLIP文本相似度达75.1(主流方法仅60-68),可生成“戴礼帽的龙宝宝”等创意模型;第二,速度快,比传统方法提速50倍,比同类模型(如3DTopia)快20倍;第三,零数据依赖,完全摆脱3D数据集限制,直接继承SD的海量知识。该方案可在1至2秒内根据文本描述生成带纹理的3D模型,对用户的创意性描述也能精准还原细节,为元宇宙、工业设计、游戏开发提供“文本即3D”的创作工具,推动AIGC从平面向立体跃迁。
马致远博士表示:“TriplaneTurbo像一位‘3D同声传译员’,将语言直接编译为网格模型。传统方法如同手工雕刻,而我们实现了3D打印级的效率——让创意不再受技术拖累。”
