
AI Industry-Academia Insights
AI行业资讯第十七期:Andrew Barto和Richard Sutton荣获图灵奖;英伟达推出专为医疗AI打造的开发者框架
发表日期: 2025年4月3日
一、2024图灵奖颁给了强化学习之父Richard Sutton与导师Andrew Barto
3月5日,美国计算机学会(ACM)宣布将2024年的图灵奖颁给Andrew Barto 和 Richard Sutton,二人皆是对强化学习(RL)做出奠基性贡献的著名研究者,他们合著的《Reinforcement Learning: An Introduction》一直是强化学习领域最经典的教材之一。
自1980年代初起,Andrew Barto和Richard Sutton将强化学习作为一个通用问题框架进行构建,并开发了许多强化学习基本算法,其中他们最重要的贡献——时间差分学习法,在解决奖励预测问题上取得了重要进展。现在,强化学习已经在机器人运动技能学习、网络拥堵控制、芯片设计、互联网广告、神经科学等多个领域发挥重大作用。ACM主席Yannis Ioannidis评价道,“Barto和Sutton的工作展示了将多学科方法应用于AI领域长期挑战的巨大潜力。从认知科学和心理学到神经科学的研究领域激发了强化学习的发展,强化学习为人工智能的一些最重要的进步奠定了基础,并让我们对大脑的工作方式有了更深入的了解。Barto和Sutton的工作并不是我们现在已经离开的垫脚石。强化学习继续发展,为计算和许多其他学科的进一步发展提供了巨大的潜力,向他们二位颁发该领域最负盛名的奖项是非常合适的。”

https://mp.weixin.qq.com/s/QC51ow-oPaEYEqjGkq5Vww
3月19日,美国圣何塞GTC(GPU技术大会)上,英伟达正式推出专为医疗AI打造的开发者框架Isaac for Healthcare。该框架整合三大英伟达计算系统,助力开发者攻克数字原型构建、AI模型训练评估、机器人策略数据收集、系统持续测试及部署应用开发等核心挑战。随后多家医疗器械领域公司纷纷响应,与英伟达展开深度合作。
- 机器人领域:Moon Surgical的Maestro手术机器人获FDA批准上市,其搭载的ScoPilot AI技术基于英伟达Holoscan技术;Virtual Incision计划利用Isaac for Healthcare开发下一代手术机器人;Neptune Medical则计划通过Isaac for Healthcare提升其胃肠机器人系统的AI能力。
- 影像领域:GE医疗深化与英伟达的合作,开发自主X射线和超声应用;Hyperfine与英伟达达成战略合作,发展其便携式脑部MRI系统;XCath则利用Isaac for Healthcare实现导管机器人自主导航的运动规划与控制。
- 脑机接口领域:Synchron与英伟达合作,推出Chiral基础模型路线图。
- 手术室领域:Artisight联合Karl Storz与英伟达打造下一代AI手术室,通过计算机视觉与环境感知自动化手术流程。

3月19日,英国爱丁堡大学在Nature Machine Intelligence发表研究成果,提出了一种名为ELLMER(具身大语言模型支持机器人)的创新框架,通过整合大语言模型(如GPT-4)、检索增强生成(RAG)、视觉和力反馈,使机器人能够在动态环境中完成复杂的长期任务。具体而言,GPT-4用于理解指令并生成任务计划,RAG从知识库中动态检索相关代码示例,视觉模块检测物体姿态,力反馈模块调整动作的力度,最后通过ROS执行生成的代码。该技术核心在于将大语言模型的“智能”与机器人的“身体”无缝结合。
在团队设计的“制作咖啡并装饰盘子”实验中,ELLMER成功完成多步骤操作,且能处理动态干扰(如杯子移动)并通过实时反馈调整动作。与基线VoxPoser相比,ELLMER任务执行的准确性从74%提升至88%。

四、谷歌发布全新基准 BBEH :推动大语言模型推理能力评估的极限
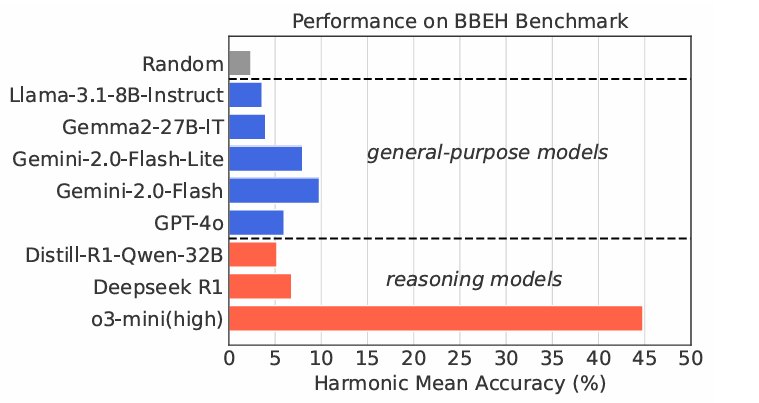
随着大语言模型(LLMs)在日常应用中扮演的角色愈发重要,对其通用推理能力和多样化推理技能的要求也在不断提高。然而,目前的推理能力评估基准大多集中在数学和编程领域,未能全面覆盖更广泛的推理能力评估需求。已有数据集 BIG-Bench因其多样化的任务设计,成为评估 LLM 通用推理能力的重要工具。但随着 LLM 技术的飞速发展,BIG-Bench 及其增强版 BIG-Bench Hard(BBH)逐渐失去了挑战性。现有最先进的LLM在这些基准上的表现已趋于饱和,无法充分反映LLM推理能力的差异与进步。为了解决这一问题,谷歌研究团队推出了全新的评估基准——BIG-Bench Extra Hard(BBEH),旨在进一步提升对 LLM 推理能力的评估深度与广度。BBEH 基准在 BBH 的基础上进行全面升级,通过用全新设计的高难度任务替代原有任务,提高了测试任务的复杂性和挑战性,从而推动LLM通用推理能力的研究。
研究团队对多个 LLM 在 BBEH 上的表现进行了详细测试。结果显示,当前最强的推理专用模型(OpenAI o3-mini)也仅达到 44.8% 的准确率。这一结果清晰地表明,在推理能力方面,LLM 仍存在巨大提升空间,尤其是在处理复杂、多样化的任务时。BBEH 的发布不仅为评估 LLM 的推理能力提供了更高的标准,也为未来模型的优化和多样化能力提升指明了方向。随着这一新基准的应用,我们有望见证更智能、更强大的 AI 模型的进一步发展,从而更好地服务于科学研究、技术创新及社会需求。
五、Meta FAIR 和纽大等提出没有归一化层的 Transformer
3月14日,来自Meta的FAIR团队、纽约大学和MIT等机构的研究者们发布了一篇论文,提出了一种名为Dynamic Tanh(DyT)的新方法。该方法能够在不使用归一化层的情况下训练Transformer模型,并且能够达到与使用归一化层相同的性能,甚至在某些情况下表现更好。
研究者们因为观察到Layer Normalization(LN)层通过类tanh的S形曲线将输入映射到输出,同时对输入激活进行缩放并压缩极值,所以受此启发,设计了一种元素级运算——Dynamic Tanh(DyT),其定义为:DyT(x) = tanh(αx),其中α是一个可学习参数。该运算通过α学习适当的缩放因子,并利用有界的tanh函数压缩极值,从而模拟LN层的行为。与传统的归一化层不同,DyT无需计算激活数据即可实现这两种效果。
实验结果表明,采用DyT的模型能够在多种设置中稳定训练,并获得较高的最终性能。此外,DyT通常无需对原始架构的训练超参数进行调整,这进一步简化了模型的训练过程。

https://arxiv.org/pdf/2503.10622
https://jiachenzhu.github.io/DyT/
Github链接:
https://github.com/jiachenzhu/DyT
3月6日,卡内基梅隆大学(CMU)团队发布论文,提出了长度控制策略优化(Length Control Policy Optimization,LCPO),显著提升了小模型的推理性能。该团队开发的15亿参数模型L1,在相同token预算下,性能可匹敌拥有2000亿参数的GPT-4o,后者参数规模是L1的133倍以上。
LCPO让模型推理过程更具灵活性,可根据任务需求动态调整「思考」长度,如同一个聪明的管家。在数学推理任务中,L1模型展现出强大的性能,与基线模型S1相比,相对提升高达100%,绝对提升达20%。此外,LCPO训练的模型不仅在标准数学推理场景中表现出色,还能泛化到分布外的任务,如逻辑推理和通用知识推理,且泛化效果良好。
更值得关注的是,LCPO训练的「长思维链」(long-CoT)模型在生成短推理时表现尤为出色。当提示要求短推理时,其性能比原始模型提升10%,即使生成长度相同。这一成果为小模型在高效推理领域的应用开辟了新的可能性。
https://arxiv.org/abs/2503.04697