
Highlights & News
CVPR 2025 | 基于贝叶斯理论的视觉语言模型的测试时间自适应
发表日期: 2025年3月17日
中国科学院香港创新研究院人工智能与机器人创新中心 (CAIR) 团队论文被国际计算机视觉与模式识别会议 (IEEE Conference on Computer Vision and Pattern Recognition, CVPR) 接收!
论文题目:
Bayesian Test-Time Adaptation for Vision-Language Models
论文作者:
周李华,叶茂,李帅锋,李念欣,朱霞天,邓磊,刘宏斌,雷震
论文链接:
http://arxiv.org/abs/2503.09248
背景:
预训练视觉-语言模型(如 CLIP)通过在大规模图文对数据上的训练,展现了强大的多模态表征能力,在图像分类等任务中表现出很好的性能。然而,在实际应用中,由于测试数据往往和预训练数据的分布存在较大差异,由此导致模型性能下降。为了解决这个问题,测试时自适应(Test-Time Adaptation, TTA)被提出用于在推理阶段实时调整模型,以适应这些未知的数据分布。目前的TTA方法通常通过调整文本提示(Prompt Tunning)或存储视觉嵌入来优化 CLIP 的适应性,但它们往往忽略了环境变化对先验知识的影响,因而限制了它们的实时性和鲁棒性。
核心创新点:
我们提交的论文提出了一种新的 TTA 方法,称为 Bayesian Class Adaptation (BCA),它能够在动态环境中提升 CLIP 的分类精度和推理效率。我们的核心创新点包括:
1. 先验的动态适应
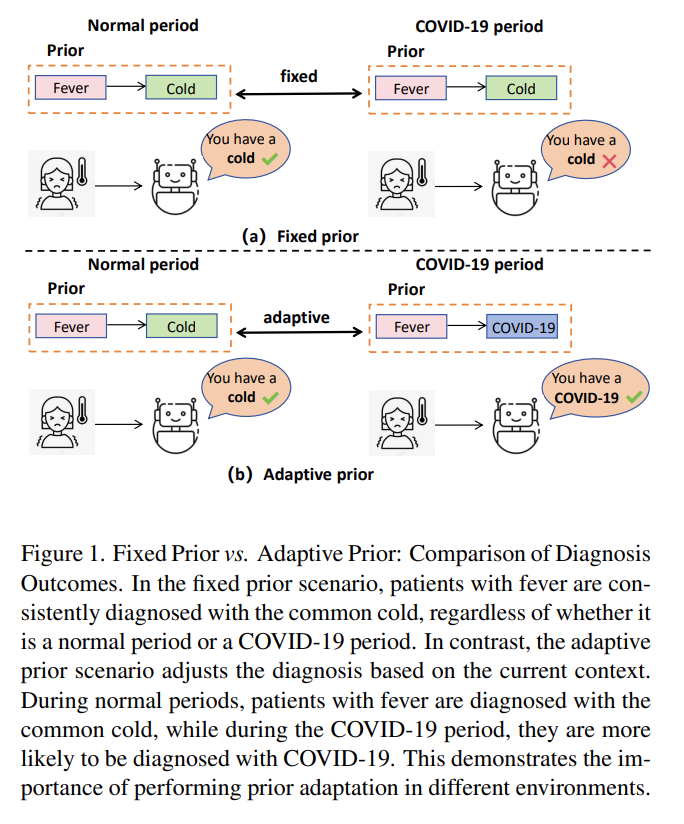
传统方法通常忽略了先验的存在,因此默认使用了一个固定的先验,缺少灵活性,而 BCA 能根据测试数据动态调整先验以适应当前数据分布。例如,如图 1 所示,在固定先验假设下,无论环境如何,发热患者都被诊断为感冒;而在自适应先验中,若处于 COVID-19 流行时期,诊断更倾向于 COVID-19,而在普通时期则更倾向于感冒。BCA 通过整合似然和先验的更新,增强了模型面对分布偏移时的适应性和鲁棒性。
2. 高效的设计
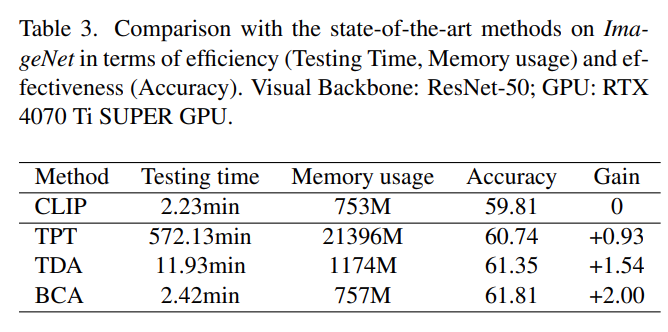
BCA 不依赖反向传播,而是通过轻量级的统计更新实时适应。在 ImageNet 数据集(ResNet-50模型)上的测试表明,BCA 的推理时间仅为 2.42 分钟,内存占用只比 CLIP 增加了约 4MB。
技术路线:
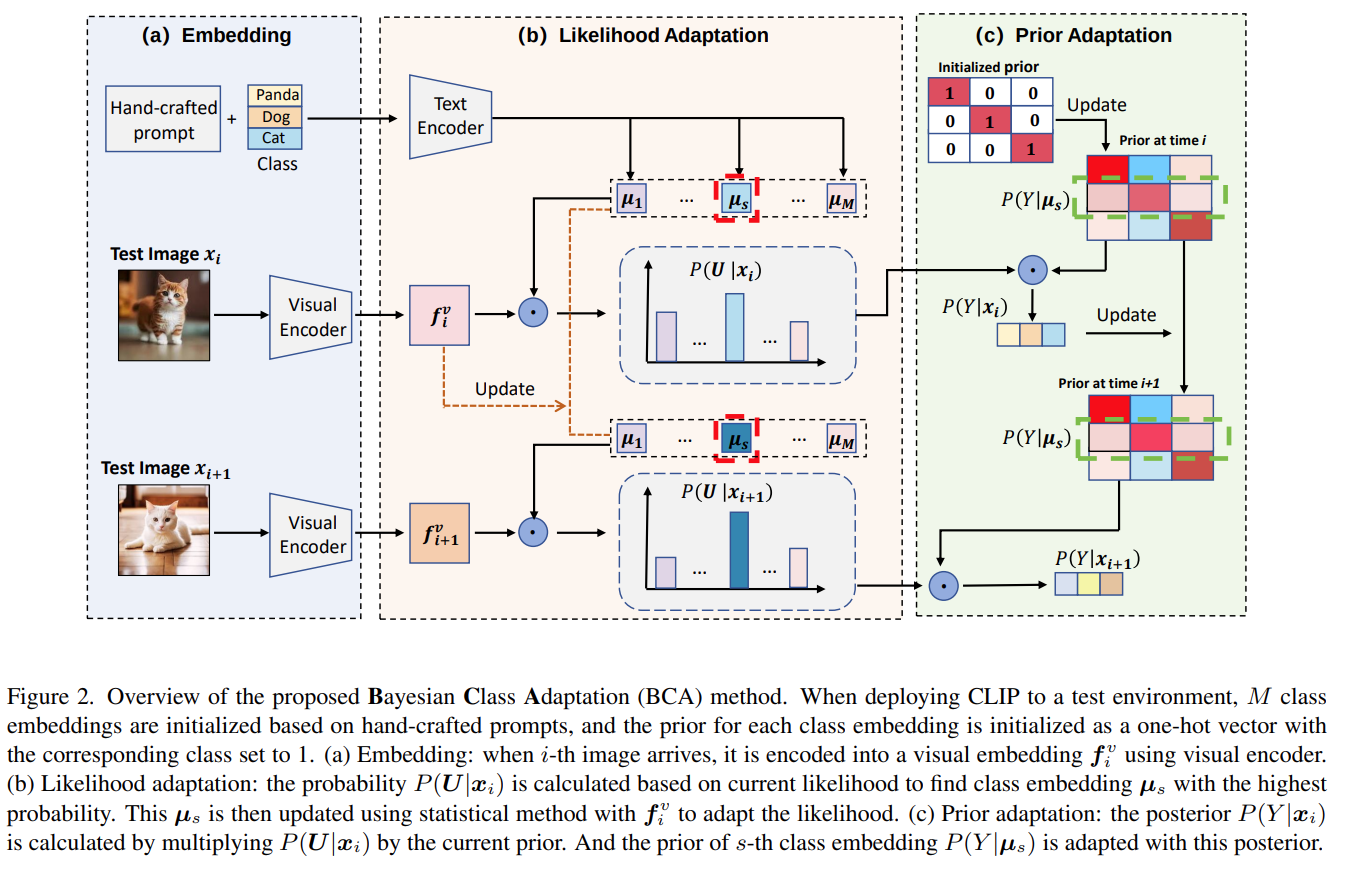
BCA 基于贝叶斯框架,将预测过程分解为两个部分:可能性和先验,并通过动态更新使模型适应测试数据。具体步骤如下:
1. 初始化
使用 CLIP 文本编码器将手写 prompt 初始化为一组 class embedding(用于后续计算可能性),并以one hot 向量(对应类别为 1,其余为 0)初始化先验向量。
2. 可能性更新
测试样本到来时,CLIP 视觉编码器生成 visual embedding,通过余弦相似度计算概率,选择最高概率的 class embedding,并使用当前的 visual embedding对选择的class embedding进行统计更新。
3. 先验更新
基于上一步选择出来的class embedding,取其对应的先验向量,然后根据对当前样本的预测更新其先验向量(后验(预测)更新先验)。
图 2 展示了 BCA 流程:第 i 个测试图像到达时,首先通过视觉编码器生成visual embedding,然后模型基于这个visual embedding进行可能性更新,即更新模型中存储的class embedding,然后再对模型执行先验更新,即调整模型中的类别先验,最终输出后验概率(预测)。
实验结果:
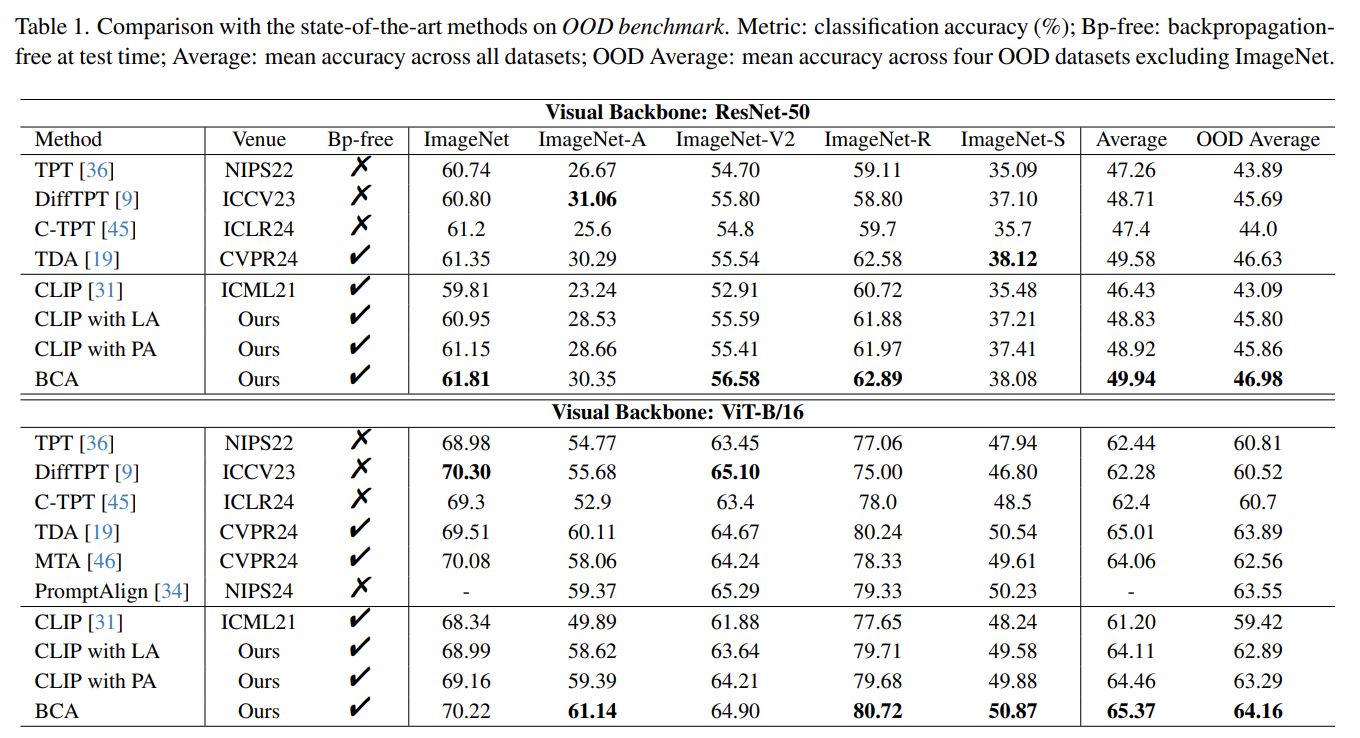
我们在 Out-of-Distribution (OOD) 和 Cross Domain 两个基准上验证了 BCA 性能:
1. ResNet-50
OOD 基准:平均精度 49.94%,OOD 平均精度(不含 ImageNet)46.98%;
Cross Domain 基准:平均精度 61.44%。
OOD 基准:平均精度 65.37%,OOD 平均精度 64.16%;
Cross Domain 基准:平均精度 65.84%。
总结:
Bayesian Class Adaptation (BCA) 通过引入先验适应并结合可能性更新,为视觉-语言模型的测试时适应提供了新思路。它在精度、鲁棒性和效率上超越现有方法,适用于动态现实场景。BCA 入选 CVPR 2025,凸显其在解决分布偏移问题上的潜力,我们期待其在未来研究与应用中的发展。