
AI Industry-Academia Insights
AI行业资讯第十六期: DeepSeek与月之暗面同时发布革命性注意力机制;清北复交教授硬核拆解DeepSeek
发表日期: 2025年3月6日
一、DeepSeek革命性NSA注意力机制问世!梁文锋上阵,长文本推理能力飙升
2月18日,DeepSeek、北大和华盛顿大学的研究人员联合发布新论文,梁文锋为作者之一。该论文发布了一项名为NSA(原生稀疏注意力机制)的全新注意力机制,具体来说它是一种面向硬件且支持原生训练的稀疏注意力机制(Sparse Attention),专为超快长上下文训练与推理设计,实现了在保证性能的同时显著提升推理速度并有效降低预训练成本。在通用基准测试、长文本处理以及基于指令的推理任务中,它的表现均能达到甚至超越传统全注意力(Full Attention)模型的水平。
NSA通过将分层token压缩与块级token选择集成到一个可训练的架构中,使得架构在保持全注意力性能的同时,实现了加速的训练和推理。在通用基准测试中它达到了全注意力的性能,长上下文评估中的建模能力更胜一筹,推理能力得到增强,同时计算延迟显著降低,实现了可观的加速:在处理64k长度的文本时,NSA的解码速度实现了11.6倍的提升,训练速度实现了高达9.0倍的前向加速和6.0倍的反向加速。

https://arxiv.org/abs/2502.11089
2月18日,就在NSA发布的同一天,月之暗面也发布了一篇内容为MoBA(块注意力混合)的注意力机制的论文,月之暗面创始人兼 CEO 杨植麟为该论文作者之一。这一架构基于混合专家(MoE)技术和稀疏注意力技术,允许模型动态选择与每个查询 token 相关的历史关键块和值块,提高了性能和效率,这对于涉及大量上下文信息的任务尤为有益。
MoBA主要包括可训练的块稀疏注意力、无参数门控机制及完全注意力与稀疏注意力的无缝切换三种机制,使模型能够自适应且动态地关注上下文中最有信息量的块,做到细致且高效地处理信息。经过一系列与全注意力(Full Attention)模型地实验证明,MoBA 在保持性能的同时显著提升了效率:在处理 1M token 时,比 Full Attention 模型快 6.5 倍;在扩展到 1000 万 token 时,较标准 Flash Attention 实现了 16 倍加速;通过块稀疏注意力机制和优化实现,MoBA 将计算复杂度从二次方降低到了亚二次方级别。这些策略使得 MoBA 的优势在序列长度增加时更为明显,特别适合处理超长文本场景。

项目链接:
https://github.com/MoonshotAI/MoBA
2月2日晚,复旦大学教授邱锡鹏,清华大学长聘副教授刘知远,清华大学教授翟季冬,上海交通大学副教授戴国浩,分别从不同专业角度分享了对DeepSeek的思考。
- 邱锡鹏聚焦DeepSeek R1的技术路线,提出强推理模型的落脚点是构建Agent框架,通过策略初始化、奖励设计、搜索和学四要素实现推理能力突破,其训练流程分为冷启动、推理导向的强化学习、拒绝抽样和监督微调、适用于所有场景的强化学习四阶段。
- 刘知远强调DeepSeek R1的贡献体现在两个方面,一是通过规则驱动的方法实现了大规模强化学习;二是通过深度推理SFT数据和通用SFT数据的混合微调,实现了推理能力的跨任务泛化。并且它通过开源复现,让全球范围内用户能够快速建立起人工智能相关能力。
- 翟季冬拆解系统架构优化,指出DeepSeek通过MLA(多头注意力机制)和MOE(混合专家模型)策略提升算力效能,并在负载均衡、通信优化、内存优化、计算优化四个方面提升训练效率,仅用550万美元左右完成所有训练。
- 戴国浩分析DeepSeek在软硬件上的优化,重点阐释其在CUDA层、PTX层的底层优化,以及打通软件硬件的协同优化,最终实现模型系统和芯片的闭环,以及“软件到硬件”+“硬件到软件”的闭环。

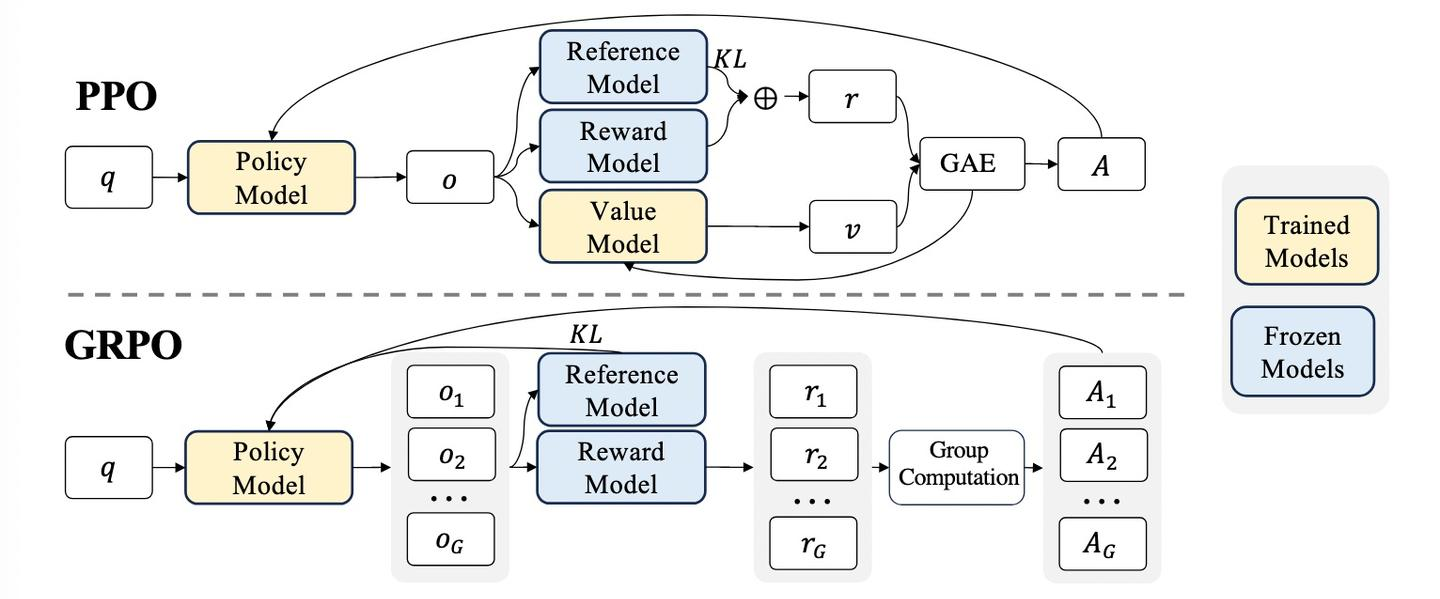
四、以字节ReFT、Kimi K1.5、DeepSeek R1为例探讨Reasoning Model的精巧实现
Kimi推出的K1.5与DeepSeek推出的R1使Reasoning Model(推理模型)引起广泛关注。本文通过探讨字节ReFT、Kimi K1.5、DeepSeek R1,分享推理模型的探索过程。这些模型摒弃了OpenAI早期推测的复杂PRM(过程奖励模型)和MCTS(蒙特卡洛树搜索)方法,转而通过在Post-Training阶段通过RL(强化学习)提升模型的推理能力。
- ReFT:ReFT核心使用PPO算法来提升推理能力,主要通过两方面优化:1) 简化Reward Model,使用Rule-Base Reward模型;2) 将Critic Model参数与Policy Model共享,压缩训练阶段模型的参数的存储空间,也进一步降低模型训练的复杂度。
- Kimi K1.5:在RL训练阶段, Kimi采用一种类Policy Gradient的方法,模型训练裁剪掉了Critic Model以减少训练的复杂度;对于Reward Model的设计较为精细,针对不同问题,不同训练阶段会调整Reward策略;在采样策略上通过课程采样和优先采样两种方法,提升训练效率。
- DeepSeek R1:DeepSeek-R1-Zero 是纯RL驱动模型训练过程,问题推理能力显著提升。DeepSeek-R1在R1-Zero基础上经过多阶段细致优,解决了可读性差的问题,提升了模型的可用性。这些优化主要包括四个阶段,即SFT→RL→增强SFT→增强RL,提升模型的推理能力。
这三个模型通过设定清晰的目标,减少人为设定,充分依托基于强化学习(RL)的端到端自驱探索能力,提供大模型推理能力的上限。
五、多家医院已部署Deepseek大模型,AI大模型在医院应用场景剖析
2月7日与10日,深圳大学附属华南医院与昆山市第一人民医院-昆山生物医学大数据创新应用实验室两家三甲医院分别完成DeepSeek本地化部署,正式开启“AI医院”建设新篇章。在临床场景中,大模型具有多种关键应用。首先,AI可以凭借卓越的自然语言处理能力构建医学知识库与智能问答系统,驱动智慧医疗;其对于病历深度智能化分析和对医学影像的精准分析,可以显著提高诊断效率与准确性;同时,搭载大模型的“智慧大脑”智能化护理机器人,将能够基于患者的个性化需求,自主完成更为多样的护理任务。此外,AI还可通过健康宣教、医院运营流程优化、医生科研辅助以及患者服务升级等多元化应用,推动医疗领域的智能化转型。
医院积极拥抱AI技术是基于深刻的行业发展背景与亟待解决的现实考量。医生数量的持续短缺、医疗资源的结构性紧张、患者日益增长且多元化的健康需求等多重挑战相互叠加,使得AI技术成为医院突破发展瓶颈、寻求创新变革的关键抓手与战略支点。值得期待的是,随着医疗智能化的革命与AI技术的不断成熟,未来的医疗AI或将真正实现"诊-疗-愈"全流程覆盖,成为医生的"全能数字搭档"。
https://mp.weixin.qq.com/s/RGpuw_L3bRZwgdp7JPOOaA
1月21日,北京大学与百川智能联合团队发布Med-R2框架。该研究通过整合检索机制与循证医学(EBM)推理流程,解决大型语言模型(LLMs)在医疗应用中的关键挑战。传统方法依赖昂贵的数据微调且易知识过时,而检索增强生成(RAG)系统则面临检索精度低、答案提取能力弱的问题。Med-R2针对性地设计了以下核心机制:
- 问题构建与分类:将医疗查询按EBM流程分类(如诊断、治疗等),并对问题重构以适应专业语境。
- 粗到细的检索策略:先通过BGE-Reranker v2-M34进行粗粒度重排,再结合证据层次、有用性评分及文档类别进行细粒度筛选。
- 链式思维(CoT)推理:利用检索证据构建推理链条,提供少量示例辅助模型生成答案,增强逻辑性与可信度。
实验验证中,Med-R2在PubMedQA等5个医疗数据集上测试了7B-70B参数规模的多款模型,结果显示:相较原始RAG方法平均提升87%,跨数据集微调中性能提升7.02%;轻量级模型(如Qwen-7B)表现尤为突出,最高提升79.72%。其核心优势源于外部知识库的多样化整合(涵盖学术文献、指南等),尤其是通过循证医学流程有效提升回答的可信度,结合粗到细检索策略优化证据质量。此外,框架无额外训练成本,在轻量级模型上即可实现显著性能增益,验证了其在资源效率与模型扩展性上的潜力。该框架为医疗领域提供了兼顾高效性、可信度与灵活性的LLM部署方案,未来或可通过动态知识更新进一步增强实用性。

清华大学生物医学工程与计算机科学系于2024年12月4日发布了一项聚焦医学多模态基础模型(MMFMs)最新发展的研究,强调了这些模型在提升临床诊断的精确度和治疗计划的个性化中的重要作用。MMFMs,包括医学多模态视觉基础模型(MMVFMs)和医学多模态视觉语言基础模型(MMVLFMs),通过整合大规模、多组织器官、多模态的数据集,展现出了优异的泛化能力,这得益于模型在多种医学图像任务上的预训练和后续的任务特定微调。这些模型在处理医学图像分割、分类、检测、配准以及临床报告生成等下游任务时展现出的高性能,证明了它们在临床应用中的巨大潜力。尽管如此,MMFMs在实际医疗环境中的应用仍然面临诸多挑战,包括但不限于数据集规模和多样性、模型在不同医学成像模态间的一致性问题,以及如何处理稀缺的标注数据。
为了克服这些挑战,自监督学习方法,如基于掩码的图像建模(MIM)和对比学习,被证明是有效的,特别是在有限的标注数据存在时。此外,多任务学习策略和复合代理任务的引入进一步提升了模型捕捉丰富多维特征表示的能力,增强了模型在多变的医学任务中的适应性和表现力。未来研究的重点将是优化多模态数据的表示方法、提升模型的鲁棒性和泛化能力,以及制定更为高效的训练策略,这些努力都将有助于推动MMFMs在临床实践中的应用和发展,为精准医疗的实现贡献力量。
