
AI Industry-Academia Insights
AI行业资讯第十三期:DeepSeek V3、Genesis震撼开源发布,AI新时代到来
发表日期: 2025年1月6日
一、DeepSeek V3横空出世:震惊AI圈
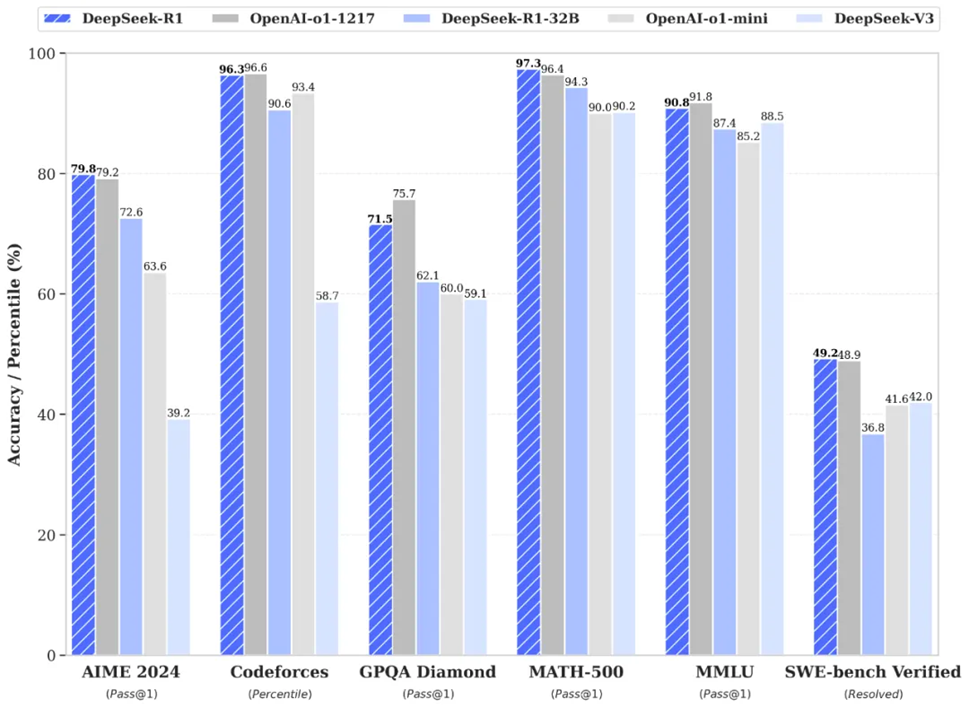
12月26日,中国科技公司研发的大模型 DeepSeek-V3开源上线,即刻引爆AI界:低成本&高效率(开发仅用了两个月和约 550 万美元,显著低于 OpenAI 和 Google 等巨头开发模型所需的数十亿美元)、性能不算落后(与OpenAI 和 Meta 的最先进模型相当,甚至在某些领域表现更佳)、打破硬件限制(使用较易获得的NVIDIA H800 晶片进行训练)、挑战现有巨头的市场优势、对投资者的启示(是否有必要投资成本高昂的前沿模型训练)。
许多人认为,这是来自东方的魔法,但实际上这个魔法叫工程科学。根据DeepSeek的技术报告,惊人的低训练价格和其强悍的能力全部有迹可循:DeepSeek-V3在预训练阶段,对性能影响有限的地方,他们选择了极致压缩;在后训练阶段,对模型擅长的领域,他们又倾注全力提升。精准启用部分「脑细胞」:其采用了一种名为「混合专家架构」的设计,简单来说,它只会在需要时启动部分「脑细胞」而不是全部,这样就大大降低了运算资源的消耗,训练该模型只使用了 2048 部 NVIDIA H800 GPU。数据处理及节能创新:DeepSeek 开发内部工具生成高质量训练数据,并使用「蒸馏技术」进一步压缩运算资源。训练过程中采用 FP8 技术,这种低精度数据格式能显著降低显存需求,同时提升效率。FP8 的使用让记忆体需求仅为传统 FP16 技术的一半,而计算性能依然不减。为进一步提升效能,DeepSeek-V3 引入多头潜在注意力(MLA)技术,能大幅压缩长文本处理时的记忆体需求,减少高达 96% 的资源消耗。同时解耦位置编码(RoPE)的加入,也确保压缩后的数据仍能准确保留位置信息,进一步提升推理速度与准确性。
Deepseek 的突破让人们看到,未来 AI 不仅能以高效能运行于高端伺服器,甚至能轻松移植到手机和平板等消费性装置上运行,让用户以低成本享受到媲美传统高性能硬件的 AI 功能,为市场带来真正的平民化技术体验。
https://36kr.com/p/3104268229054209

四、Nature子刊报道:内镜垂体手术的AI辅助解剖识别

https://shorturl.at/V8jAK
五、Nature Communications报道:革命性的便携式低场磁共振成像技术

https://www.nature.com/articles/s41467-024-54972-x

https://www.bilibili.com/video/BV1csq5YCEtg/
https://www.bilibili.com/video/BV1qjqfYoE3t/?spm_id_from=333.337.search-card.all.click