
AI Industry-Academia Insights
AI行业资讯第十五期:DeepSeek重磅推出R1和多模态模型引爆全球!创始人梁文锋霸气宣言“中国要成为全球创新的贡献者”
发表日期: 2025年2月8日
一、DeepSeek-R1发布,性能对标OpenAI o1正式版
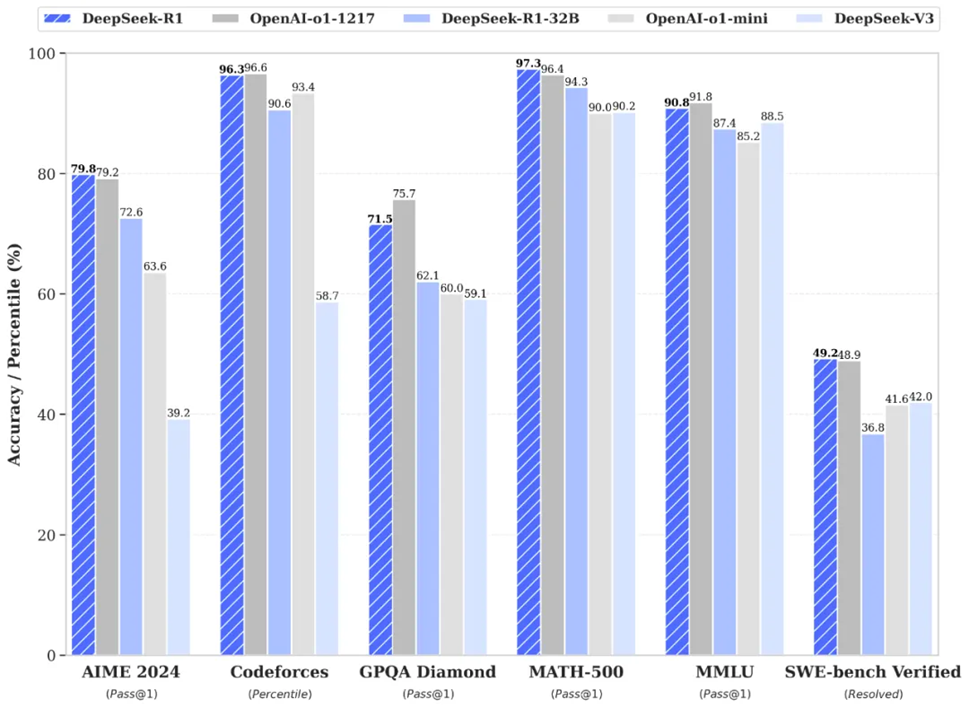
1月20日,继DeepSeek-V3之后,DeepSeek再次推出并开源了推理大模型DeepSeek-R1,该模型性能可比肩 OpenAI o1 正式版。除此之外,DeepSeek还开源了6个从DeepSeek-R1蒸馏而来的小型模型。其中,32B和70B模型的性能同样可以与OpenAI-o1-mini相媲美。DeepSeek-R1 API 服务定价亲民,每百万输入 tokens 仅1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 仅16 元。
为了不用监督微调(SFT)作为冷启动,而是通过大规模强化学习显著提升模型的推理能力,该团队还开发了DeepSeek-R1-Zero,其具有以下三点独特设计:一是采用群组相对策略优化(GRPO)降低训练成本,二是采用准确性奖励与格式奖励系统,三是设计了一种训练模板来引导基础规则。在训练过程中,DeepSeek-R1-Zero 展现出了显著的自我进化能力,并学会了通过重新评估初始方法来更合理地分配思考时间。
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
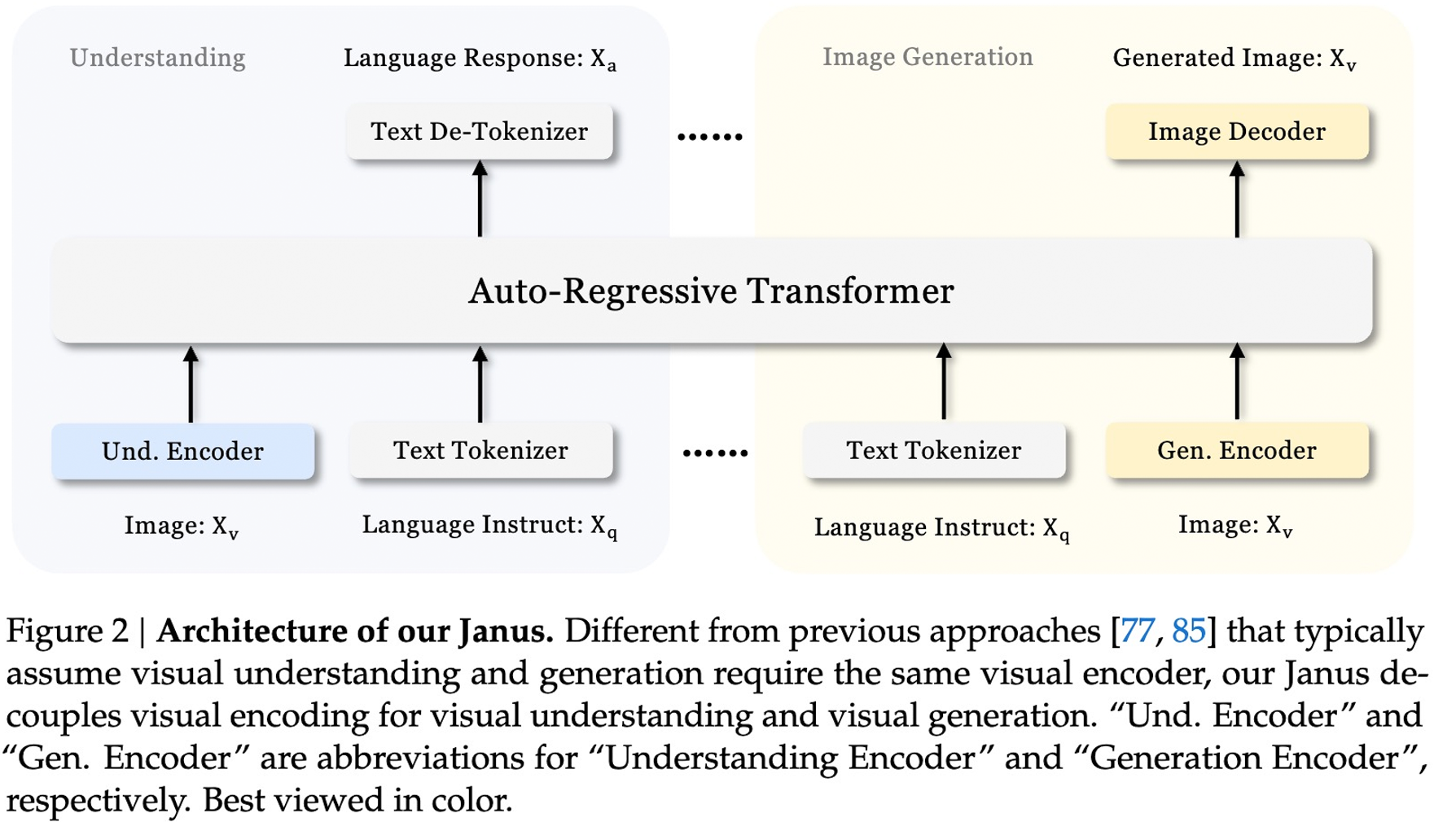
训练策略优化:精炼训练过程,更有效地建模图像中的像素依赖关系,以及更有效地利用文本到图像数据; 数据扩展:扩展了多模态理解和视觉生成的训练数据,包括合成美学数据的整合; 模型扩展:将模型从 10 亿参数扩展到 70 亿参数,证明了这种方法的可扩展性。
代码:
https://github.com/deepseek-ai/Janus

四、英伟达CEO黄仁勋CES 2025演讲:人工智能正以惊人的速度发展

https://shorturl.at/V8jAK
五、1760亿参数医学大模型MedFound问世
https://www.nature.com/articles/s41591-024-03416-6

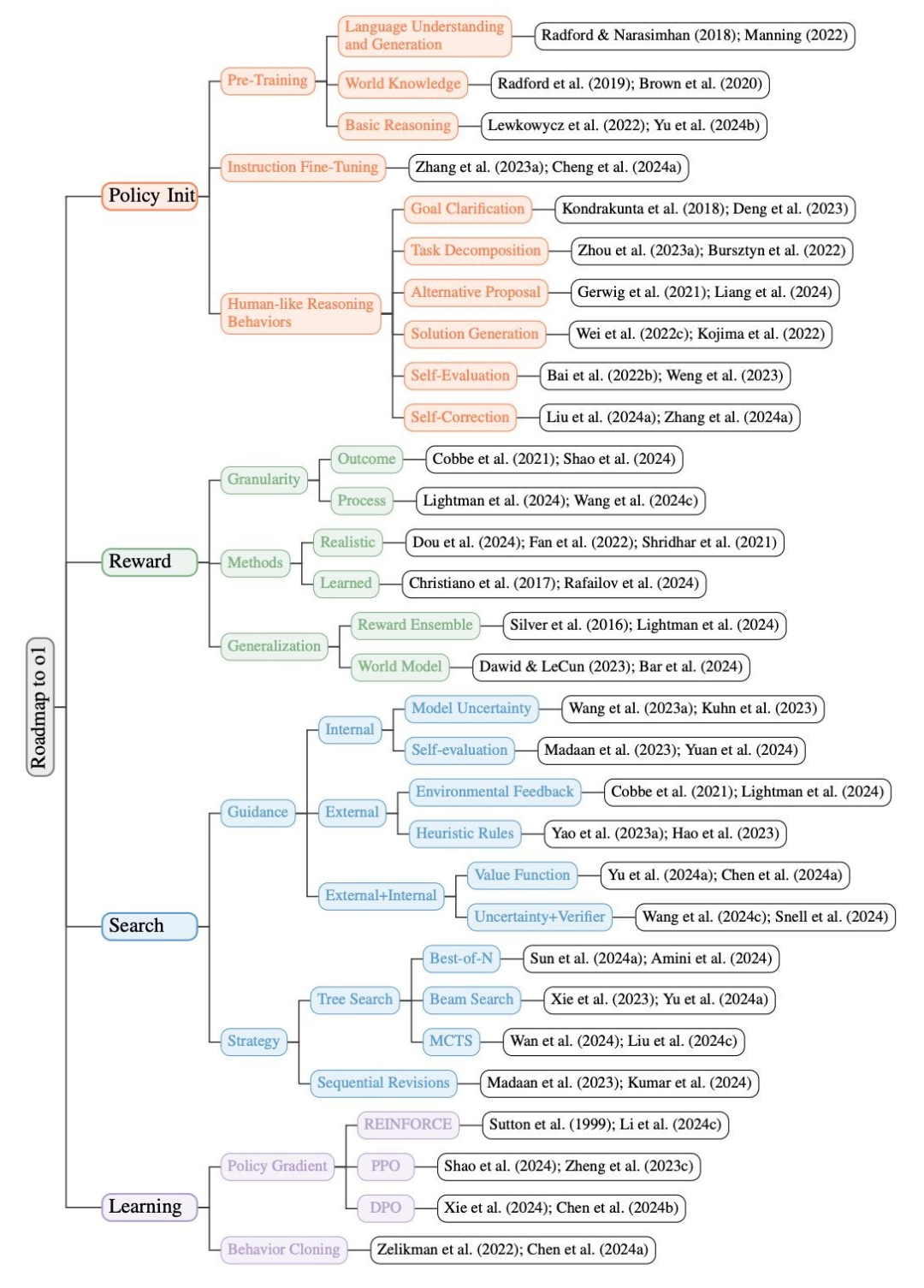
策略初始化:使模型能够发展出「类人推理行为」,从而具备高效探索复杂问题解空间的能力。 奖励设计:通过奖励塑造或建模提供密集有效的信号,指导模型的学习和搜索过程。 搜索:通过更多计算资源可以生成更优质的解决方案,在训练和测试中都起着至关重要的作用 学习:强化学习通过与环境的交互进行学习,避免了高昂的数据标注成本,并有可能实现超越人类的表现
https://arxiv.org/abs/2412.14135
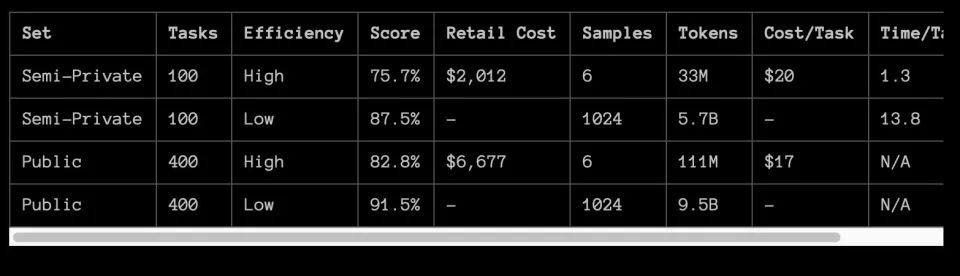
https://mp.weixin.qq.com/s/0Yo-kRGtQS3aIKoFzBaGaw
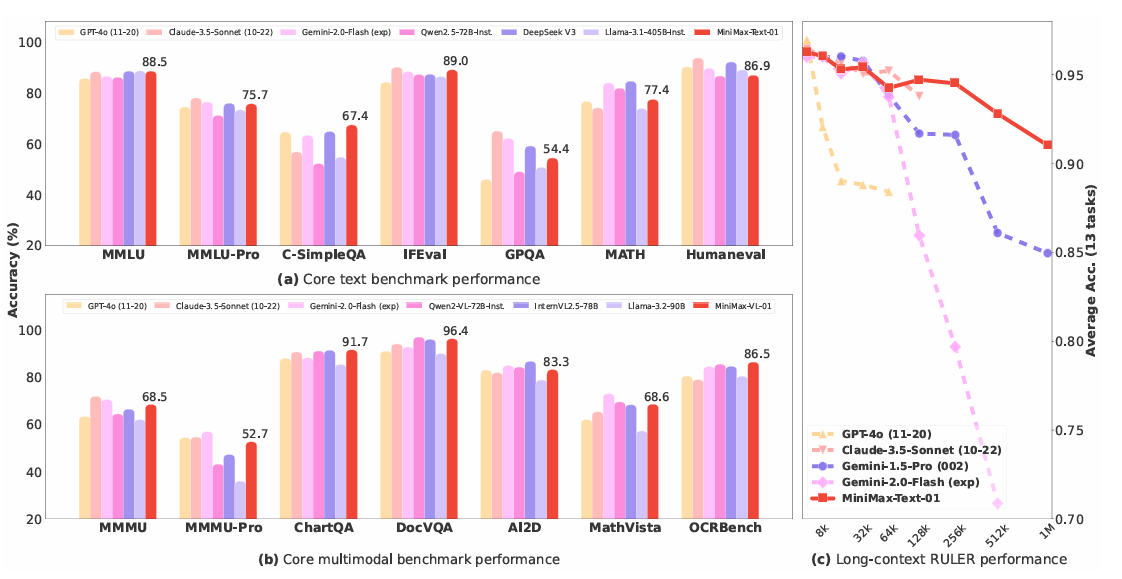
https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf