
AI Industry-Academia Insights
AI行业资讯No.30:DeepSeek-V4 震撼发布;术影手术视频大模型下载量登顶;元智医疗视频理解大模型开源;Agent Harness引领智能体范式变革
发表日期: 2026年5月15日
1.DeepSeek-V4 震撼发布!架构、训练、基础设施全面升级
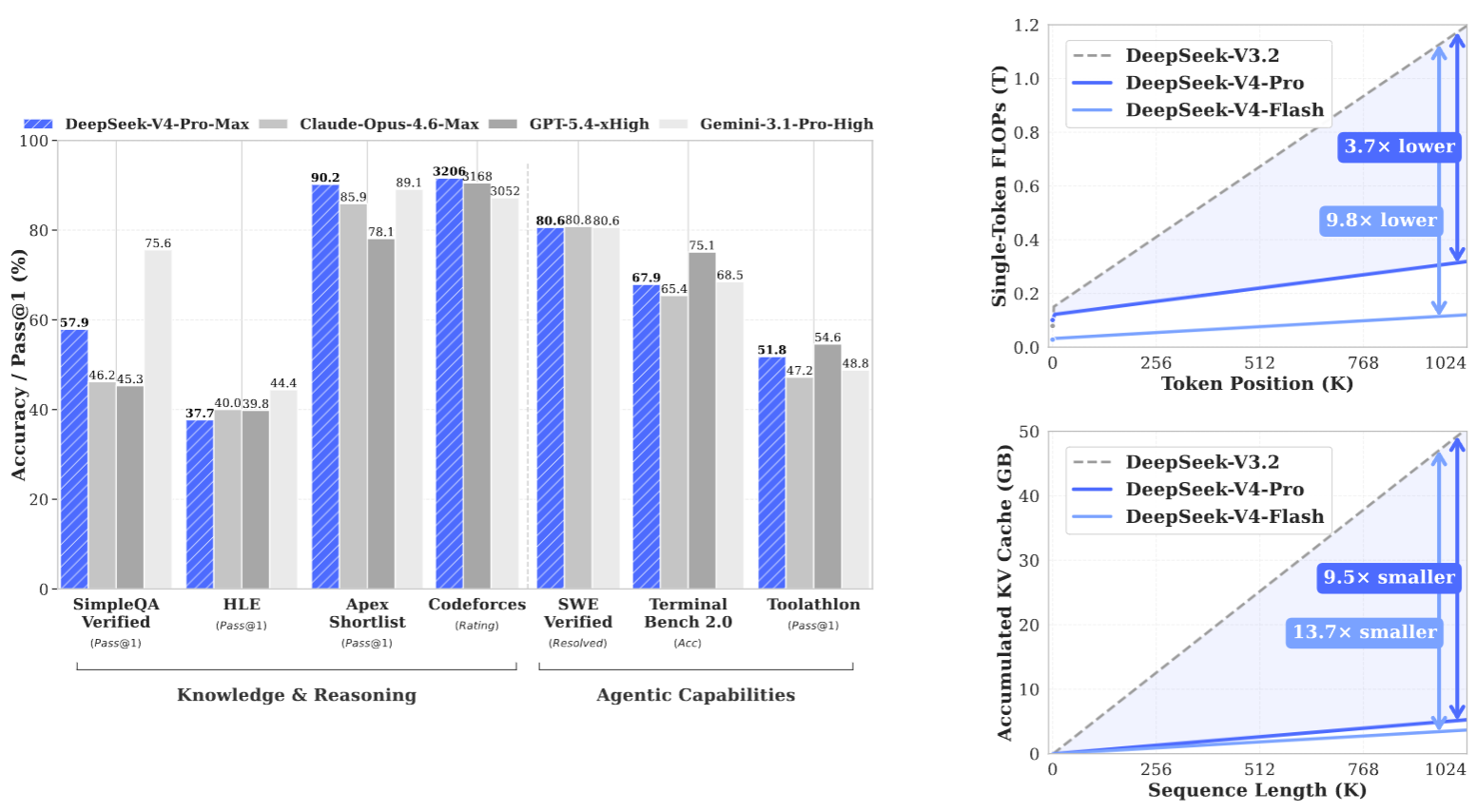
4月24日,深度求索正式发布全新大模型 DeepSeek-V4,并同步开源。该模型具备百万 Token 超长上下文处理能力,综合性能可对标国际顶尖闭源大模型,同时已完成与华为昇腾等国产芯片厂商的全面适配与生态兼容。
在架构层面,DeepSeek-V4 完成多项关键升级,搭载混合注意力、流形约束超链接与 Muon 优化器,提升长文本处理、表征能力及训练收敛稳定性。同时实现全链路工程优化,达成计算可复现;依托低精度计算降低资源消耗,上下文长度突破百万 Token 级别。
预训练阶段,DeepSeek-V4 采用超 32 万亿 Token 高质量多元语料,覆盖数学、代码、长文档等领域。通过样本级注意力掩码、优化数据清洗流程、筛选合规网页数据规避模型崩溃,融入智能体数据增强代码能力,扩充多语言与长文档语料,实现综合能力全面提升。
后训练阶段,DeepSeek-V4 创新采用策略式蒸馏方案,以高质量数据监督微调为基础,结合 GRPO 算法开展领域强化学习,打造专属专家模型。同时优化底层机制,释放智能体交错推理效能,工具调用留存完整推理历史,支撑长周期智能体任务连贯逻辑迭代。
基础设施上,DeepSeek-V4 推出 MegaMoE 细粒度 EP 方案,实现通信计算重叠,适配英伟达及华为昇腾平台并大幅提升推理速度;借助融合内核降低调用开销,以 Z3 求解器保障比特级可复现,通过 FP4 量化节省显存、优化长上下文注意力计算。
DeepSeek-V4 突破了超长上下文处理中的效率瓶颈,通过融合 CSA 与 HCA 的混合注意力架构,并结合系统级基础设施优化,使模型能够更高效地支持百万 Token 级上下文,为测试时扩展、长时序任务和在线学习等方向筑牢技术基础。
链接:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2.长文本性能天花板,华为昇腾超节点全系全面支持 DeepSeek-V4
4月24日,依托底层算力优化能力,昇腾超节点全系列产品全面适配 DeepSeek-V4 系列模型。其中,昇腾 950 融合多种量化算法,显著提升推理性能,实现 DeepSeek-V4 模型高吞吐、低时延部署。
底层架构方面,昇腾 950 完成三大核心升级:全面兼容 FP8、MXFP8、MXFP4 等数据格式,在保障模型精度的同时,内存占用降幅超 50%、算力实现翻倍;针对 MoE 模型离散访存特性,增强硬件级稀疏访存能力,有效破解专家路由过程中的带宽瓶颈;创新存储架构打通向量单元与矩阵单元内存通路,大幅降低端到端推理时延。同时,该架构支持基于 NAND SSU 实现超低成本、超大容量、高性能 KV Cache,有力支撑长序列应用场景,可适配万卡级 Scale-Out 集群规模。
昇腾 950 超节点通过融合内核与多流并行技术,削减 Attention 计算及访存开销,刷新长文本推理性能上限。在 8K 输入场景下,DeepSeek-V4-Pro 模型 TPOT 约 20ms;DeepSeek-V4-Flash 模型 TPOT 约 10ms 时,单卡 Decode 吞吐可达 1600TPS;TPOT 约 20ms 时,单卡 Decode 吞吐达 4700TPS。昇腾 A3 超节点搭载 DeepSeek-V4-Flash 模型,基于 vLLM 推理引擎,单卡 Decode 吞吐可达 2000+TPS,产品性能持续优化迭代。
针对自定义算子开发门槛高、研发周期长的行业痛点,昇腾 CANN 推出 PyPTO 编程范式,配备完备 Python API,依托高效算子开发、高性能 Kernel 自动生成、PTO ISA 虚拟指令集跨代兼容及 TileLang 完善社区生态,支持开发者采用 Python 原生语法快速完成算子开发。
昇腾超节点是国内唯一实现成熟规模化商用的超节点产品,可满足大模型超高吞吐、超大并发的高性能需求。昇腾 A2、A3、950 全系列产品均适配 DeepSeek-V4-Flash、DeepSeek-V4-Pro 模型,以极致算力实力与开放生态布局,助力 AI 产业高质量发展。

链接:https://www.modelscope.cn/organization/Eco-Tech
3.真正读懂手术,业内最强手术视频大模型SurgMotion发布
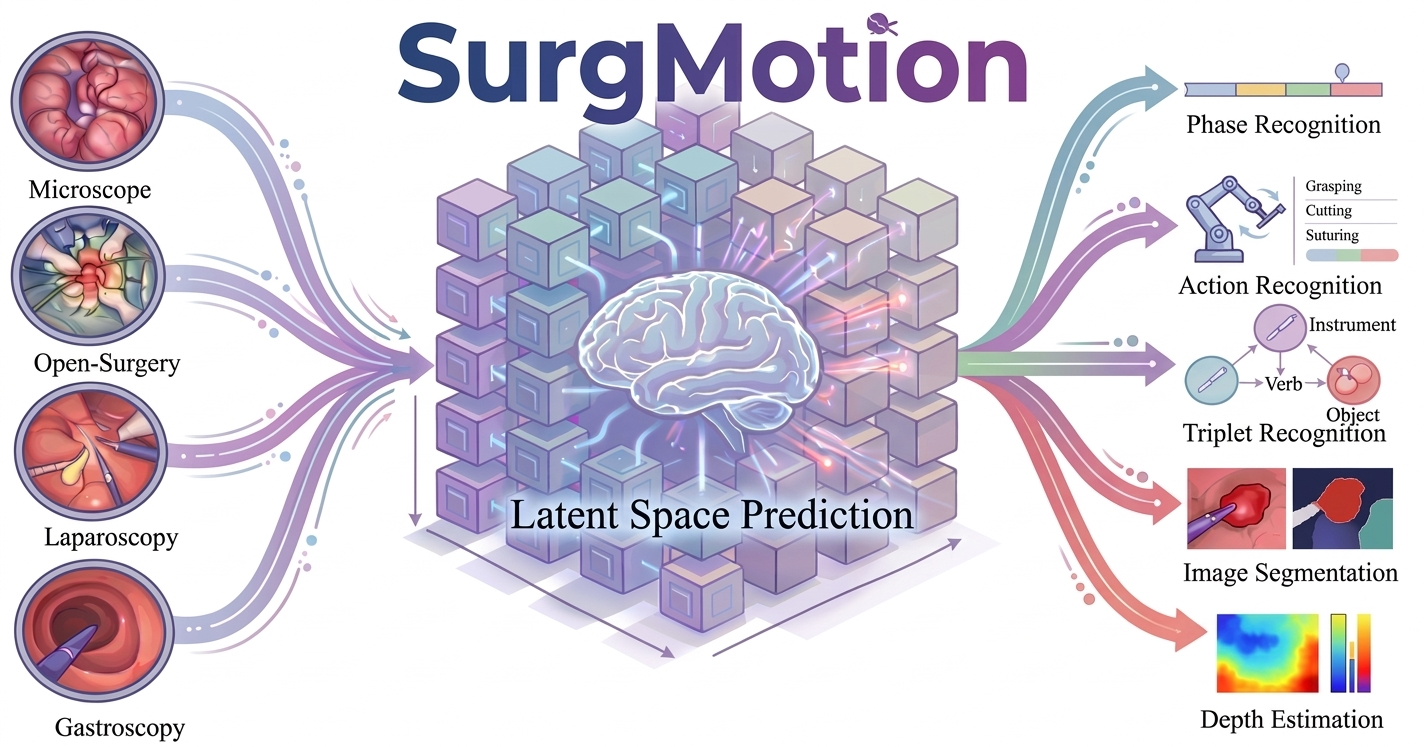
3月24日,中国科学院香港创新研究院人工智能与机器人创新中心开源发布了 “术影” SurgMotion 手术视频大模型,标志着外科手术 AI 从 “碎片化识别” 向 “通用化理解” 的跨越式进化,为临床治疗、手术操作、医学教学及术后复盘提供有力支撑。
针对传统自监督学习方法易将算力和模型容量浪费在低层次细节的问题,SurgMotion 在 V-JEPA 架构基础上,引入运动引导的隐空间预测、特征多样性保持和模型稳定性保持三项技术改进,让模型更专注于学习手术视频中的运动和中高层语义信息,实现了更高效的自监督训练。
同时,团队构建了目前规模最大的手术视频预训练数据集,汇集来自 50 个数据源、约 1500 万帧、超 3658 小时的真实手术视频,涵盖腹腔镜、开腹、神经外科、眼科、耳鼻喉科等多专科场景,为模型训练提供了充足且全面的数据支撑。
该模型可支持 13 种人类主要器官、6 大类手术理解任务,包括工作流理解、动作理解、深度估计、息肉分割、三元组识别、技能评估,且已在 17 个国际权威手术 AI 基准上全面刷新最优纪录(SOTA)。尤其在手术流程识别、器械交互理解、精细动作建模等核心任务上,其性能大幅超越现有方法,展现出极强的泛化能力与识别精度。
应用验证中,该模型表现突出:在香港大学深圳医院神经外科培训领域,准确率高达 90%;在公开的 JIGSAWS 手术技能评估数据集中,评估误差最低降至 2.649,与专家评分相关系数达 0.770,性能远超同类模型;在中山大学附属第一医院呼吸介入治疗流程识别中,准确率约 85%。
目前,在 GitHub 等开源社区,“术影 ”SurgMotion 的下载量位居全球同类模型首位,其标准化分析能力,可有效降低复杂手术风险,显著提升临床诊断与手术操作的规范性,为各级医疗工作者提供强有力的技术支持。
链接:https://surgmotion.cares-copilot.com/
4.打破手术视频黑盒!联影智能开源其医疗视频理解大模型
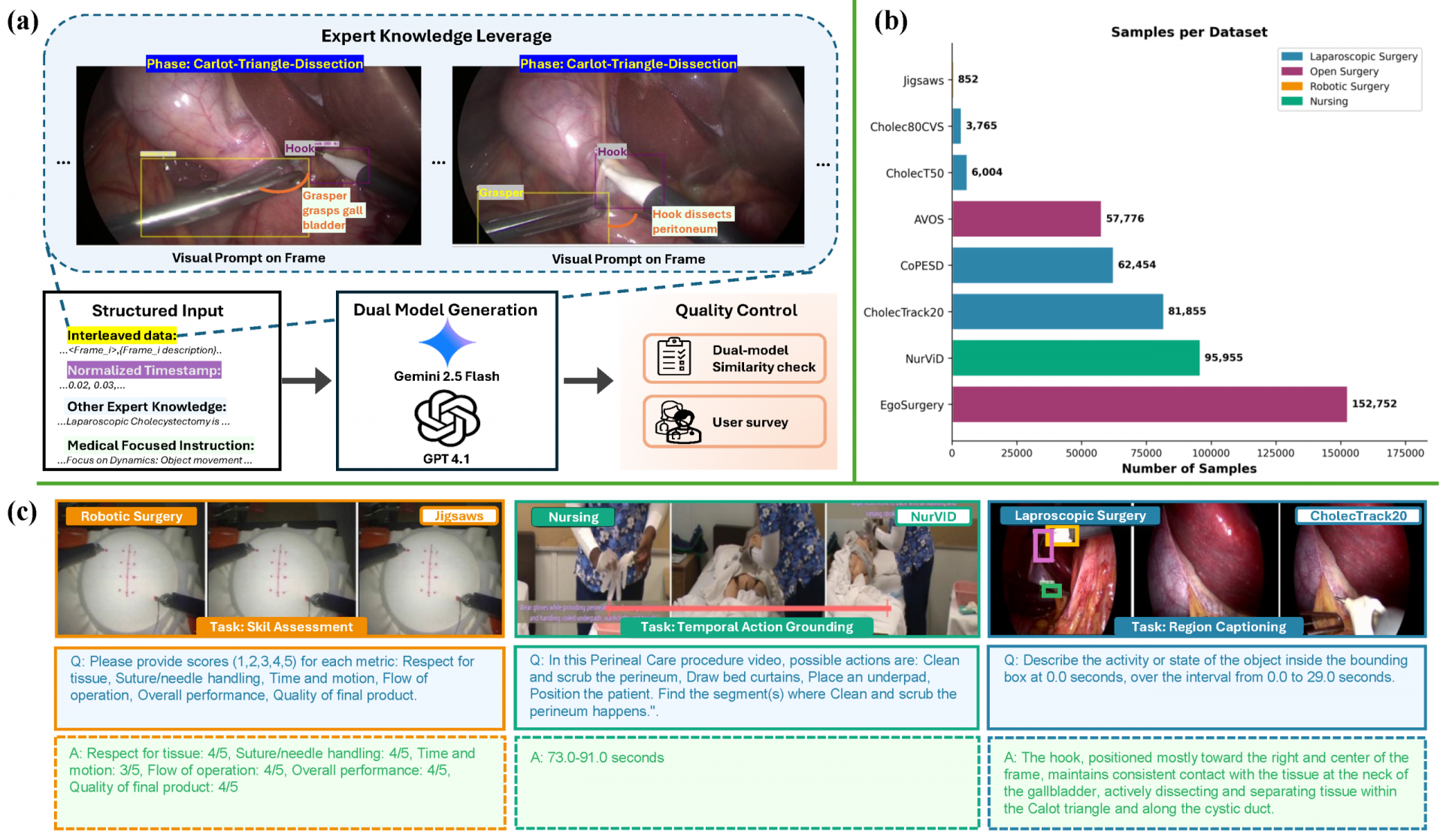
4月24日,联影智能开源全球首个医疗视频理解大模型 uAI Nexus MedVLM,相关成果已被 CVPR 2026 收录。同时,同步发布的 6245 组精标测试集及全球首个医疗视频理解公共评测体系,填补了行业空白。
该模型以数据源头优化为核心,通过对海量医疗视频进行逐帧级精细标注,精准覆盖器械类型、空间位置、手术操作、风险评估等核心要素,经持续训练与迭代优化,具备强大的视觉理解能力,构建起覆盖多场景的感知、推理、决策能力体系。
性能方面,模型基于超 53 万精标数据训练,在 4B、7B 参数规模下表现突出:手术安全评估准确率达 89.7%,远超 GPT-5.4 的 16.4% 和 Gemini-3.1 的 24.2%;时空动作定位任务中,预测区域与真实区域的交并比分别是 Gemini-3.1 的 3.2 倍、GPT-5.4 的近 47 倍;视频报告生成评分 4.24 分,显著领先两款对比模型。
应用场景上,模型覆盖内镜腔镜、开放式手术、机器人手术及护理操作等多类临床场景,在视频摘要、关键安全视野评估、下一步操作预测等八大核心任务中表现卓越。
此外,联影智能开放了一套由 6245 个视频 - 指令对构成的标准测试集,为医疗视频理解提供更具可比性的评测基准;同时上线了医疗视频理解大模型榜单,开发者可提交自有模型结果,系统依据统一标准自动评分,形成动态更新的统一排行榜。
uAI Nexus MedVLM 的成功发布,标志着医疗视频 AI 正式迈入面向全球开发者的黄金时代。未来,该模型将进一步深入融合具身智能技术,打造成为打通医疗影像、临床决策与物理执行的智能枢纽,进而推动复杂医疗操作全面迈向数字化、结构化与智能化转型。
链接:https://uii-ai.github.io/MedGRPO/
5.从拼模型到拼工程, Agent Harness引领智能体范式变革
近日,LangChain 创始人提出项目定位正从 Agent Framework转向 Agent Harness,标志着 AI 行业从打造单体智能体,进阶到构建智能体生态体系,也催生了 Harness Engineering 全新开发范式。工程师不再以编码为核心,转而聚焦环境设计、意图定义与反馈闭环搭建,Agent Harness 成为这一范式的核心支撑。
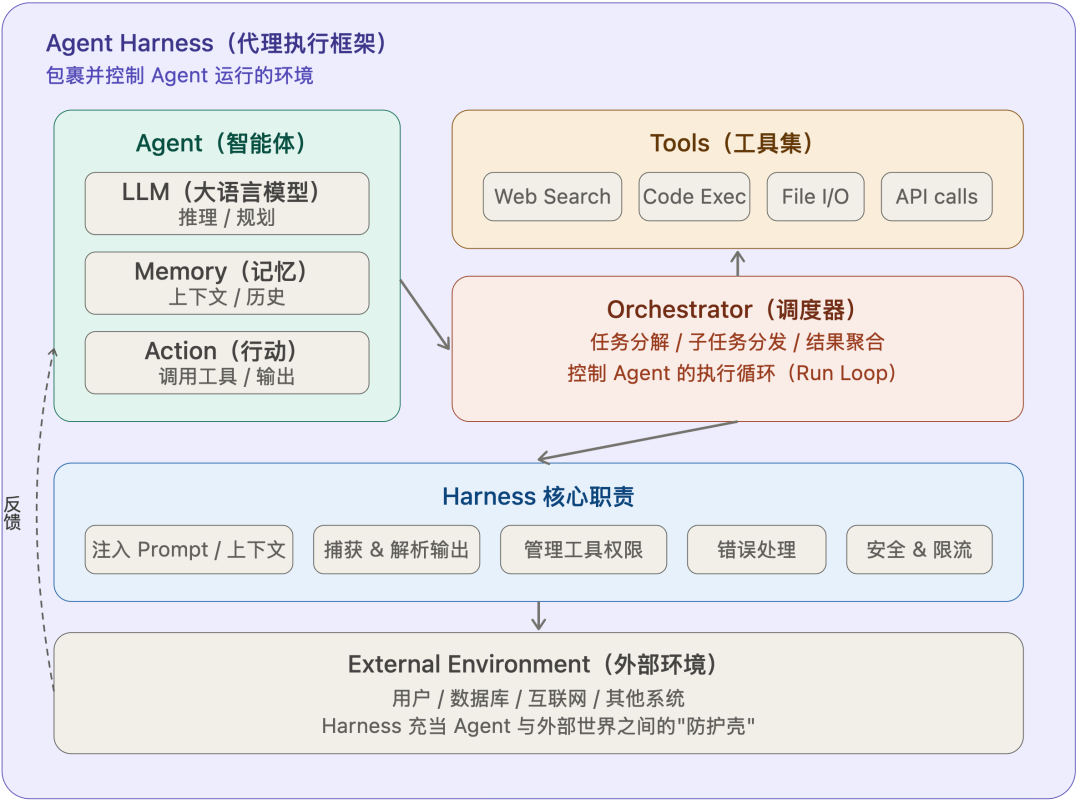
Agent Harness 是围绕大模型 / AI Agent 搭建的结构化工作环境与治理工程体系,其核心逻辑是不改变模型本身能力,通过规则、流程、文件规范等外部改造,让普通模型稳定完成复杂长任务。形象类比的话,模型是 CPU,上下文窗口是内存,Harness 则相当于 “操作系统”,负责调度分工、状态管理与行为约束,核心思路是拆分任务、分段接力,通过外置文件记录进度,实现多 Agent 高效协作。
Harness 主要通过三层形态落地,其中仓库级实践是核心:工具内置层为平台固定机制,不可修改;仓库级通过专属文档定义项目标准、流程,搭配进度日志与自动测试钩子,最能体现其本质;组织级则通过企业 AI 网关、审计日志实现全局合规。
Harness 的核心价值是推动 AI 开发从 “拼模型” 转向 “拼工程”,催生 AI 工业化生产。它能突破上下文窗口限制,通过任务拆分与进度存档解决长任务记忆不足问题,支撑 AI 完成百万行代码生成等复杂工程;同时规范 Agent 行为,实现多 Agent 无人值守协作,还能适配医疗、法律等专业领域需求,降低 AI 落地门槛。
未来,随着上下文窗口迭代,Harness 的工具编排、多 Agent 协调、权限治理等核心功能将愈发重要,成为 AI 从对话工具走向工程化、行业化智能体的底层框架,长期价值聚焦于扩展模型行动边界、规范行为与提升协作效率。
链接:https://zhuanlan.zhihu.com/p/2021872485772043815
6.覆盖颅脑全疾病,天坛医院发布CT辅助报告生成大模型
4月24日,北京天坛医院发布全球首个覆盖颅脑全疾病的 CT 辅助报告生成大模型 “小君医生 2.0”,1 分钟内即可生成一份全面、精准的诊断报告初稿,为精准医疗发展注入新活力。
不同于目前医学影像 AI 领域常见的 “单病种工具”,该模型实现了 “全病种覆盖” 的突破。它以天坛医院海量高质量颅脑 CT 影像数据为基础,结合多 AI 大模型技术架构研发而成,可同时感知颅脑 11 个解剖部位的 94 种疾病,解读 1232 个诊断术语。无论是出血、缺血、肿瘤等致命性严重疾病,还是鼻窦炎、颅底钙化等易被忽视的轻微病变,都能被精准捕捉,大幅降低漏诊风险。
该模型不仅能生成常规诊断报告,还可完成术后报告,自动提取病灶关键变化,生成与既往影像的对比分析。使用过程中,系统会主动提示可能遗漏的重要征象,校验诊断术语是否符合医院规范,对比本次与前次报告的差异,实现 “智能质控”,让报告更规范、更严谨。
初步测试显示,80% 以上的常规病例,医生对 AI 生成的报告初稿只需小幅修改甚至无需修改;对于复杂病例,放射科医生原本需 5—10 分钟完成报告,借助该模型,审核修改仅需 2—3 分钟。这一转变,将医生从繁重的重复性书写中解放出来,构建起 “AI 生成初稿、医生审核定稿” 的高效诊疗模式。
“小君医生 2.0” 能充当医生的 “在线专家分身”,提供标准化诊断模板和鉴别诊断提示,既帮助医生规避漏诊、规范书写,也能助力年轻医生快速提升疾病认知,加速成长。
链接:https://www.bjtth.cn/Html/News/Articles/214507.html
7.破除数据孤岛,南方医院与华为发布医院通用人工智能平台
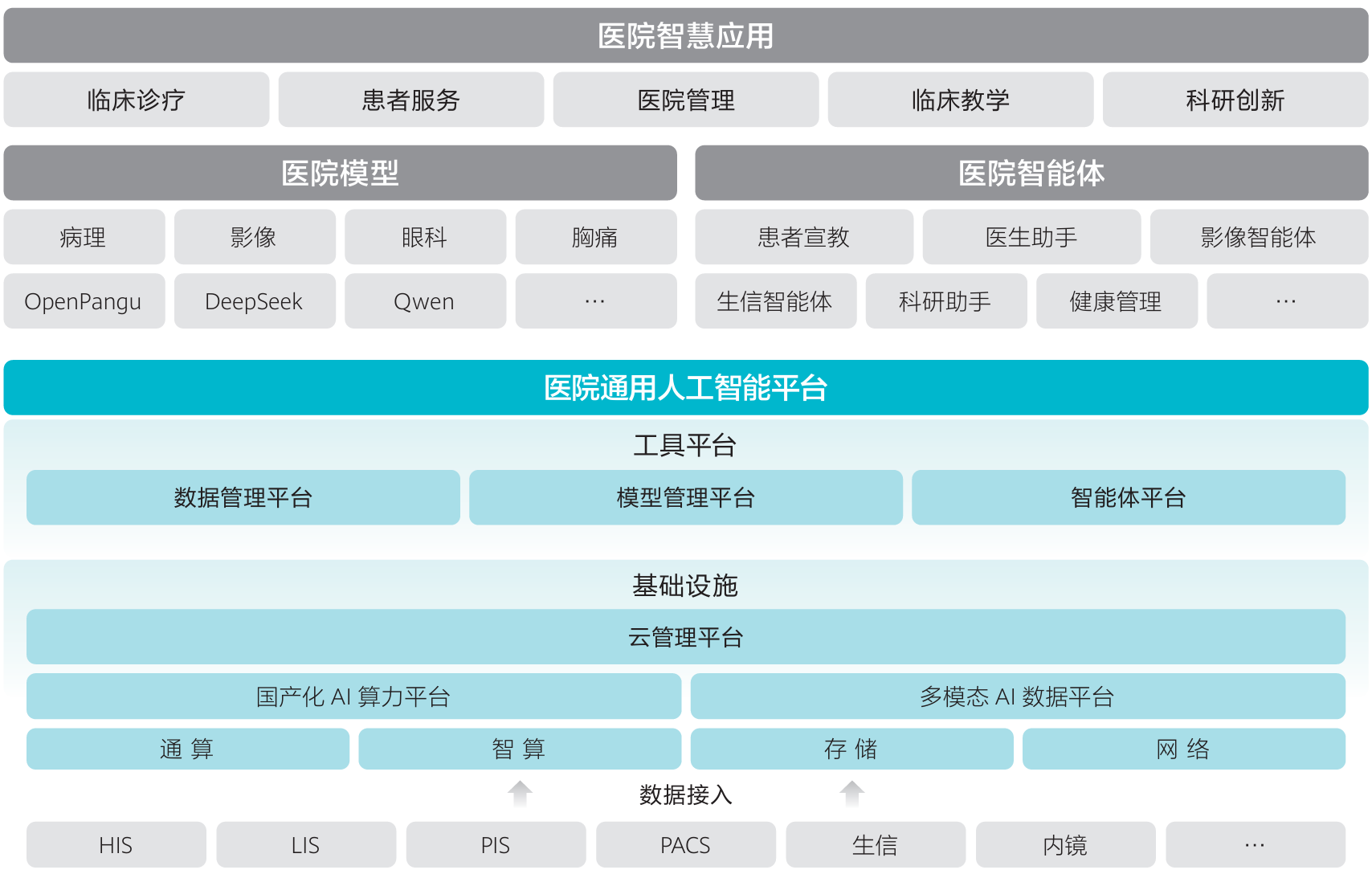
4月10日,南方医院携手华为面向全球正式发布医院通用人工智能平台(HAIP)及《医院通用人工智能平台技术白皮书》,标志着智慧医疗发展迈入全新范式。
HAIP 定位为医院专属 AI 操作系统,核心价值在于统筹全院算力、数据与模型资源,整合碎片化 AI 能力,搭建可共享、可进化、可向基层医疗机构赋能的一体化数智底座,推动医疗 AI 建设从单点零散部署、碎片化应用,转向统一整体规划、全院全域协同的全新发展模式。
HAIP 采用 “能力底座、智能中枢、工具引擎” 三位一体架构,依托昇腾、鲲鹏等国产算力基座,建成 100% 自主可控的 AIDC 算力集群;DCS AI 容器底座实现算力切分与智能调度,使 AI 算力利用率提升 30% 以上。平台通过 AI 数据湖破除数据孤岛,筑牢 AI 训练 “数据粮仓”,可实现毫秒级检索响应,有效提升模型推理准确率。
平台依托 ModelEngine 工具平台,实现全类型数据智能标注与多模态 AI 语料生成,以数据飞轮机制驱动模型持续优化。平台具备 NL2Agent 自然语言生成能力,医护人员无需掌握编程即可打造专属数字分身;多智能体协同架构可支撑三甲医院与基层医疗机构之间,实现 AI 模型自动化部署、迭代与升级。
同步发布的技术白皮书,系统阐释 HAIP 设计理念、技术架构与应用场景,明确医疗 AI 建设核心需求与解决方案,为全国智慧医院 AI 平台化建设提供标准化参考与实践指引。
目前,南方医院已在临床诊疗、患者服务等领域落地多项医疗 AI 应用。未来,医院将依托 HAIP 与 HAIC 的云边协同架构,完善医院级 AI 资源体系,推进全场景智慧医院建设,为全球医疗机构输出可复制、可推广的智慧医院建设路径。
链接:https://e.huawei.com/cn/news/2026/industries/healthcare/general-artificial-intelligence-platform-hospitals