
AI Industry-Academia Insights
AI行业资讯 No.27:首个大规模 AI 乳腺癌筛查结果出炉;全球最强医疗模型百川 M3 发布;英伟达开放高效推理模型 Nemotron 3……
发表日期: 2026年2月11日
1.AI辅助筛查媲美双人阅片,MASAI试验结果发布
1月30日,《柳叶刀》发布了全球首个大规模AI乳腺癌筛查随机对照试验(MASAI)的研究成果。这项历时五年的研究覆盖了超过10.5万名女性,结果显示:AI辅助筛查在筛查质量上媲美传统双人阅片,同时将放射科医生的阅片工作量减少了44%,显著提高了筛查效率。
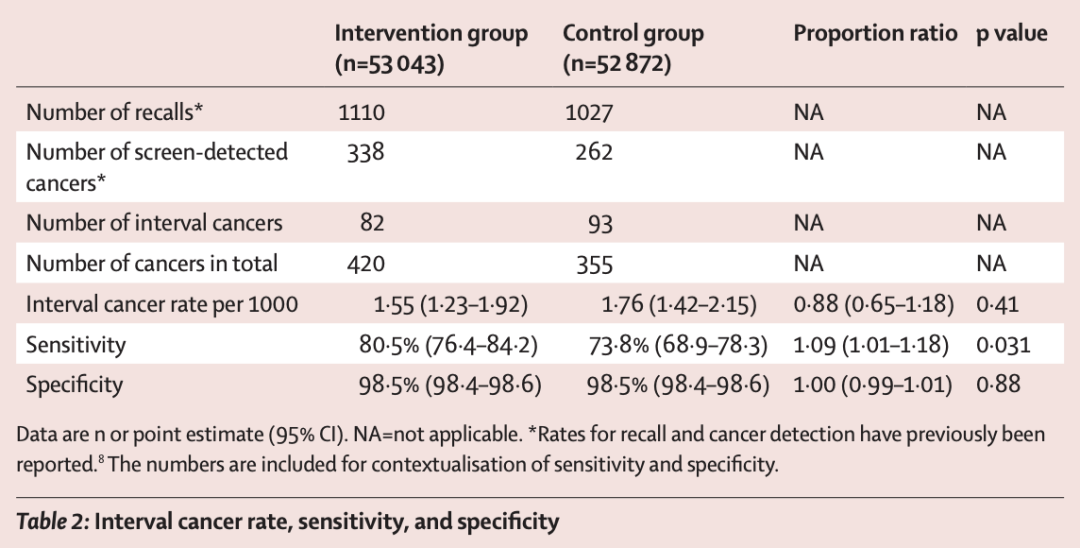
MASAI试验采用前瞻性、随机化、大样本的研究设计。数据显示,AI组与对照组的间期癌发生率分别为每千人1.55例和1.76例,敏感性分别为80.5%和73.8%,特异性均为98.5%。AI辅助筛查多检出29%的癌症,尤其是早期、小体积的侵袭性癌症,这有助于降低间期内晚期癌症的发生概率。然而,AI的应用也可能增加过度诊断的风险,需要在实际应用中进一步权衡利弊。
与MASAI类似,英国国家医疗服务体系(NHS)已启动迄今为止规模最大的AI乳腺癌筛查前瞻性研究——EDITH试验。该试验计划招募近70万名女性,在30个筛查点测试5种AI平台,以验证AI的适用性和效果。在监管层面,美国FDA已通过510(k)途径批准了数十款AI诊断产品,其中包括首个通过DeNovo途径获批的AI风险预测平台Clairity Breast。
尽管MASAI试验仍存在一定局限性,但其为医疗AI领域提供了重要的方法参考。研究团队指出,未来需要进一步分析后续筛查数据、评估成本效益,并验证AI在多元人群和不同临床场景中的应用效果。这一成果为缓解全球乳腺影像学领域的人力短缺提供了切实可行的解决方案。
链接:https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(25)02464-X/abstract
2.AI医疗奇点已到,全球最强医疗模型百川M3发布
1月13日,百川智能发布并开源了新一代医疗增强大语言模型Baichuan-M3。这不仅是模型参数的升级,更是对AI医疗的重新定义,标志着从被动答题向严肃问诊的重大转变。
Baichuan-M3的核心突破在于首次具备原生的端到端严肃问诊能力。该模型依托SCAN原则(安全分层、信息澄清、关联追问)和SPAR算法,能够在有限轮次内精准提取关键信息,将患者的主观描述转化为医生可理解的结构化临床数据。
为从源头抑制AI幻觉,Baichuan-M3构建了一套事实感知强化学习架构。在训练中引入严苛的事实验证,相当于为模型植入实时“审稿人”,有效防止信息编造,使医疗幻觉率成功降至3.5%,刷新全球纪录。
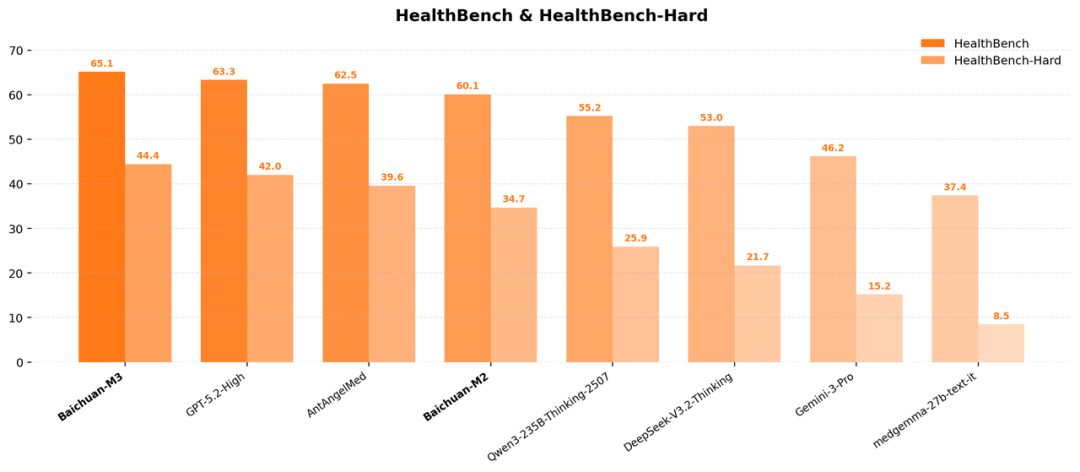
在全球权威医疗AI评测HealthBench及其高难度子集HealthBench Hard中,Baichuan-M3击败GPT-5.2,实现全面SOTA。此外,百川智能还搭建了涵盖病史采集、辅助检查、精准诊断的SCAN-bench评测体系,对Baichuan-M3进行全流程动态考核。结果显示,Baichuan-M3问诊准确度显著领先于人类医生基线及全球顶尖模型,并在流程规范性、知识广度和指南遵循方面展现出超越人类的稳定性,体现了强大的潜力。
目前,百川智能旗下医疗应用“百小应”已全面接入Baichuan-M3,不仅成为患者24小时在线的全科医生助理,而且极大地优化医生了诊疗流程,显著提升了问诊效率与准确性,真正实现了“强推理、低幻觉的医疗服务能力”落地。
链接:https://huggingface.co/baichuan-inc/Baichuan-M3-235B
3.推理效率提升4倍,英伟达发布Nemotron 3开放模型
近日,英伟达发布了 Nemotron 3 系列开放模型,包括 Nano、Super 和 Ultra 三种参数规模。其中,Nemotron 3 Nano 已在 Hugging Face 上线,是当前效率最高的模型,Super 和 Ultra 预计将于 2026 年上半年推出。
Nemotron 3 采用 Mamba-Transformer 混合 MoE 架构,通过交替堆叠低成本的 Mamba-2 层,仅保留少量自注意力层以优化效率,解决了 KV Cache 的计算和存储问题。其核心技术包括:
LatentMoE:在低维空间进行专家路由,降低通信成本并提升模型表达能力;
多 Token 预测:一次预测多个 Token,提高推理效率与准确性;
NVFP4 低精度训练格式:优化训练性能,提升吞吐量;
超长上下文支持:支持长达 100 万 Token,避免传统 RoPE 的上下文扩展限制;
多环境强化学习后训练:提升准确性与泛化能力;
精细化推理预算控制:根据任务复杂度动态调整推理深度、性能与成本。
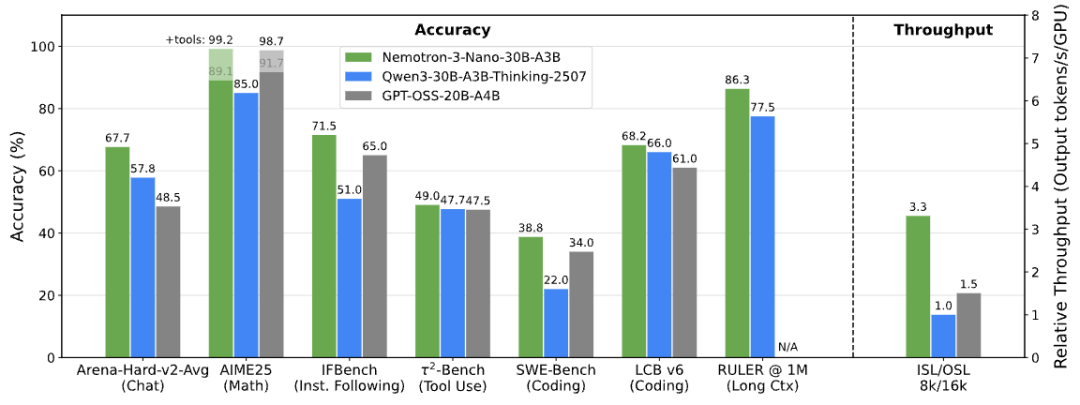
在性能测试中,Nemotron 3 Nano 表现优异。其 30B-A3B 模型的准确率超过 GPT-OSS-20B 和 Qwen3-30B 系列。在单张 H200 GPU、8K 输入 / 16K 输出的配置下,其推理吞吐量是 GPT-OSS-20B 的 2.2 倍,Qwen3-30B 的 3.3 倍。
为支持开发者,Nemotron 3 Nano 已开源多种模型版本、数据和模型配方,发布了覆盖推理、编程、多步骤任务的 3 万亿 Token 数据集。此外,英伟达推出 NeMo Gym 和 NeMo RL 库 提供训练环境,并开放 NeMo Evaluator 用于模型性能评估。目前,Nemotron 3 已获得 LM Studio、llama.cpp、SGLang 和 vLLM 的支持,帮助开发者高效构建专业化 AI 系统。
链接:https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-White-Paper.pdf
4.万亿参数+Agent集群,Kimi K2.5 正式开源发布
1月27日,月之暗面发布了新一代MoE开源基础模型Kimi K2.5。该模型不仅拥有1万亿参数,还展现了卓越的视觉理解、编程能力和智能体协作能力。
与前代相比,Kimi K2.5不仅能够处理视频,还支持“图像转代码”功能,用户无需提供提示词或编写代码,仅通过设计稿即可生成目标代码,极大提升了便捷性,同时展现了出色的“设计审美”。其编程助手Kimi Code可无缝集成至VSCode等主流IDE,支持通过图片和视频输入生成代码,并能够自动迁移用户技能到工作环境,进一步优化开发效率。
Kimi K2.5的核心亮点在于引入了Agent Swarm(智能体集群)功能。该功能能够动态调度多达100个智能体并行工作,最多支持1500次工具调用,处理速度较单智能体提升4.5倍。基于PARL并行强化学习框架,Kimi K2.5能够高效分解复杂任务,显著缩短执行时间。智能体集群还支持高密度办公任务,包括文档、电子表格、PDF和幻灯片的处理,能够生成专家级输出。
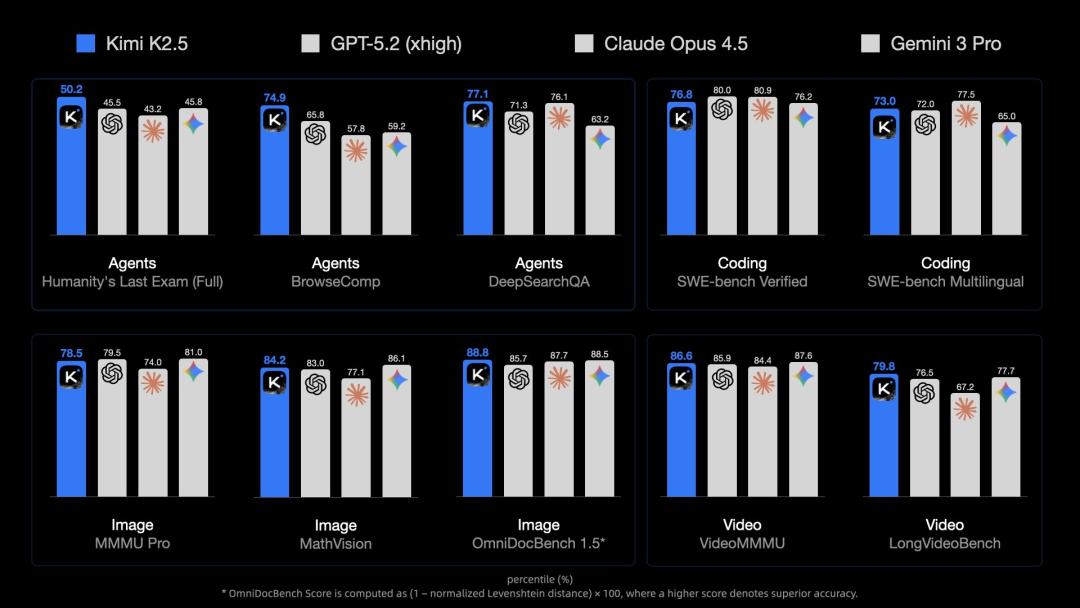
在多项专业评测中,Kimi K2.5的成绩达到开源领域的最佳水平(SOTA),例如HLE 50.2%、BrowseComp 74.9%和SWE-bench Verified 76.8%。在部分关键基准测试中,其表现甚至超越了当前最强大的闭源模型(如Opus 4.5、GPT 5.2X High和Gemini 3.0 Pro),但运行成本仅为这些模型的几分之一。
基于视觉理解与智能体能力的持续突破,Kimi K2.5已经达到前沿模型的水平,尤其是在解决复杂任务方面,其智能体集群模式表现尤为亮眼,树立了全球开源大模型的新标杆。
链接:https://www.kimi.com/blog/kimi-k2-5.html
5.DeepSeek提出Engram 条件记忆机制和 视觉模型OCR 2
1月,DeepSeek 相继开源发布多项最新研究成果,包括 Engram 条件记忆模块和 DeepSeek-OCR 2,展示了其在大模型稀疏化和视觉编码领域的领先技术能力。
Engram 条件记忆模块作为混合专家(MoE)条件计算的补充,基于哈希 𝑁-gram 实现稀疏检索,具备 O(1) 时间复杂度的知识查找能力。通过静态记忆检索与上下文融合,Engram 减轻了浅层网络的静态模式重建负担,增强了模型的复杂推理能力,并通过多级缓存扩展记忆容量,突破显存限制。实验结果表明,Engram 在知识、推理、代码和数学任务上显著优于传统 MoE 模型。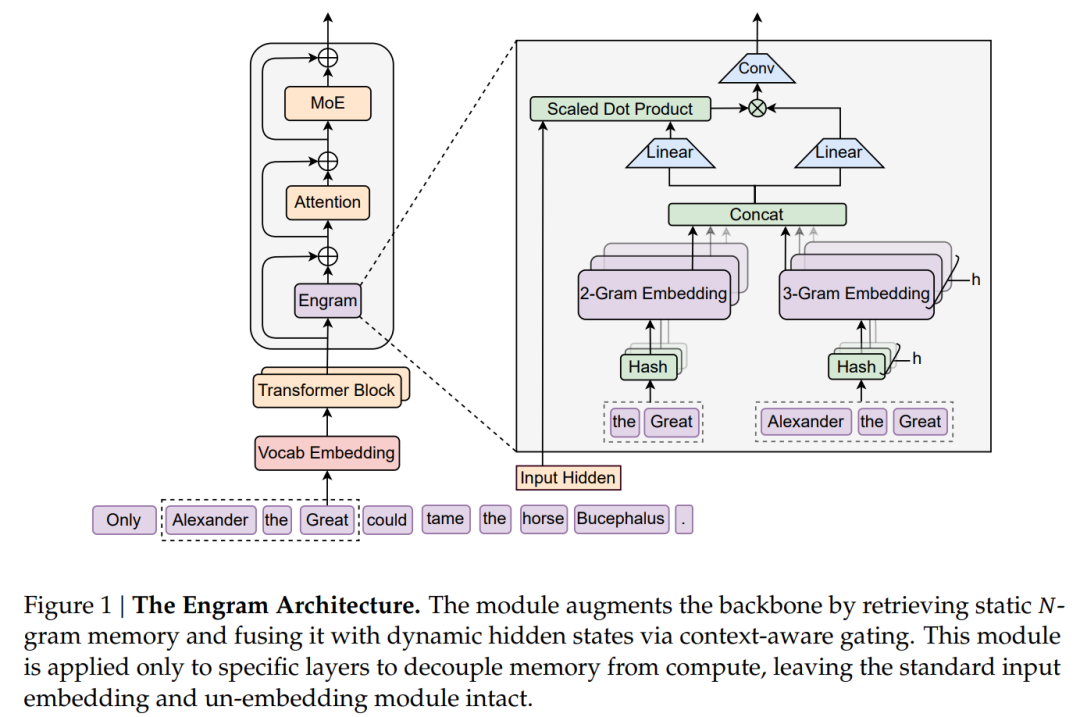
DeepSeek-OCR 2 则通过全新的 DeepEncoder V2 实现从固定扫描到语义推理的视觉编码升级。模型引入因果流查询机制和语言模型 Qwen2-500M 作为视觉编码器,动态重排视觉 Token,精准还原复杂文档的阅读逻辑,仅用 256-1120 个视觉 Token 就可覆盖复杂文本页面,OmniDocBench v1.5 综合得分达 91.09%,较前代提升 3.73%。此外,模型在提升逻辑性和应用能力的同时,显著降低了 OCR 重复率。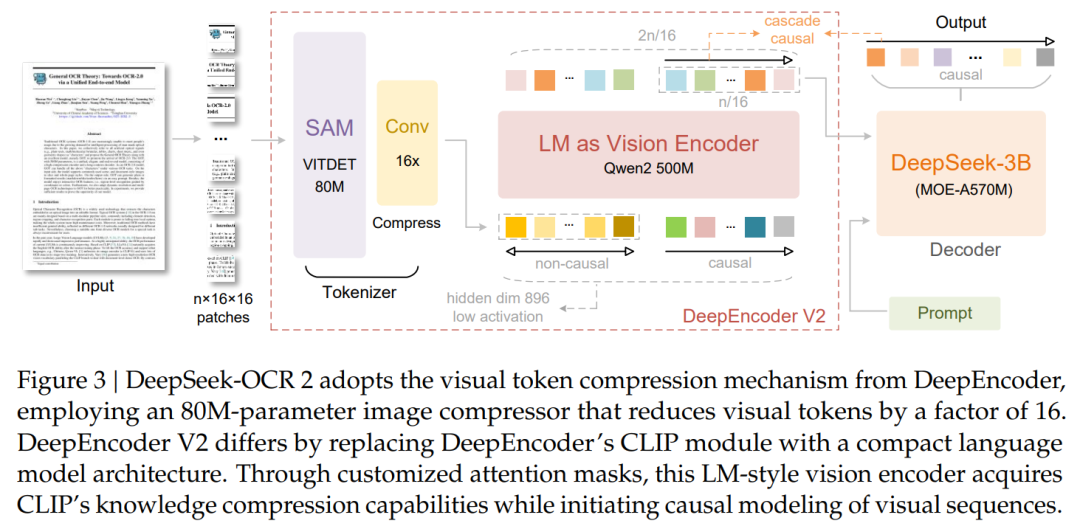
这些架构创新不仅为深度学习模型的知识检索和视觉理解开辟了新路径,还进一步推动了多模态统一编码器的构建,更为即将到来的 DeepSeek v4 奠定了坚实基础,有望再次重塑全球 AI 技术格局。
Engram链接:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
DeepSeek-OCR-2链接:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
6.为超节点而生,昇思MindSpore 2.8版本正式发布
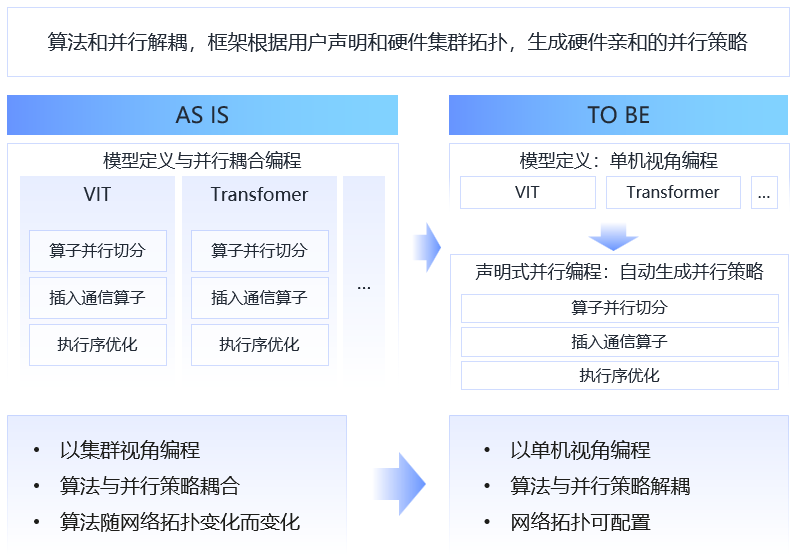
1月28日,昇思MindSpore 2.8版本正式发布,通过引入专为超节点环境设计的HyperParallel架构,显著提升了人工智能模型在训练和推理过程中的灵活性与效率。该版本关键特性如下:
采用声明式并行范式,解耦并行策略与模型逻辑,融合超节点调度与全局协同。用户以单卡视角编写代码,系统自动推导分布式策略,支持多模态大模型组装,开创“Triton范式”,实现“编写即单卡,运行即分布式”的高效体验。
实现全图层次化存储管理,提升显存效率与吞吐量;增强动态图能力,支持Dispatch、saved_tensors_hook和算子级注册机制,优化大模型训练与推理。同时,框架开放自定义算子、PASS和后端接口,灵活优化计算图,适配专用硬件,满足多场景需求,推动AI高效落地。
支持SGLang与vLLM v0.11.0,集成MindSpore后端,适配DeepSeek-V3、Qwen3等SOTA模型。通过vLLM升级接入ACLGraph功能,优化算子图下发,提升吞吐性能5%,减少推理延迟至10ms,为大模型推理提供高效解决方案。
通过重计算技术和分块计算模式,显著提升了长序列训练与推理的性能,同时优化了核心算子与 JIT 编译策略,解决性能与内存瓶颈,推理性能提升超100%,单卡Token长度突破3000,端到端加速达57%,为科学研究提供了高效工具。
MindSpore 2.8 全面强化自定义能力,优化分布式训练效率,提升大模型推理性能,在大规模计算任务处理上取得重大突破,为AI开发者和研究人员提供更高效、更灵活的创新工具与技术支持。
链接:https://www.mindspore.cn/version-updates/zh/2_8